

从今以后,所有淘宝天猫商家都能一键图生视频了
从今以后,所有淘宝天猫商家都能一键图生视频了这两年,大模型作为前沿技术,正逐步深入电商行业的各个环节。 2025,这一变革仍在加速:近日,【淘宝星辰 · 图生视频】工具已重磅上线,并对淘宝天猫商家正式开放!
来自主题: AI资讯
12791 点击 2025-01-13 14:22
这两年,大模型作为前沿技术,正逐步深入电商行业的各个环节。 2025,这一变革仍在加速:近日,【淘宝星辰 · 图生视频】工具已重磅上线,并对淘宝天猫商家正式开放!
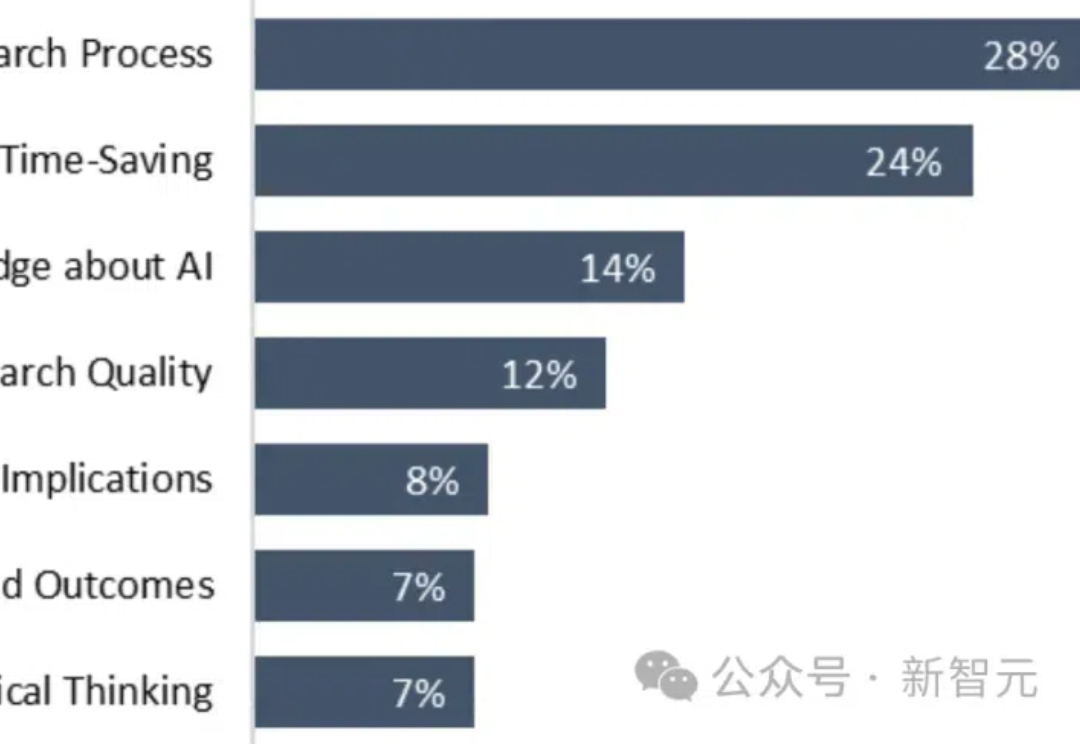
Nature子刊近日发布了一项研究,针对学术写作中大模型的使用。他们发现,那些了解LLM以及大模型相关技术的受访者有更多的发表文章数量。

每天,全球有数亿人在向AI产品倾诉他们的想法、困惑、创意,甚至秘密。但鲜有人意识到,这些对话正在以“帮助训练下一代AI模型的”的名义,突破着过往移动互联网产品的数据使用界限。

2024年11月15日,加州理工学院生物学和生物工程系的Jieyu Zheng和Markus Meister发表了一篇震撼学界的论文《The Unbearable Slowness of Being: Why do we live at 10 bit/s?》[1]。这项研究揭示了一个令人不安的事实:人类大脑每秒仅能处理大约10比特信息。

MuseAI 是由阿里集团爱橙科技研发的面向阿里内部的 AIGC 创作工作台,同时通过与阿里云旗下魔搭社区合作共建的形式,将主体能力通过魔搭社区的 AIGC 专区对公众开放。

随着 AI 技术的突飞猛进,其进步几乎每天都在刷新人们的认知,很多人都在猜想,AI 是否会在不久的将来取代人类医生?
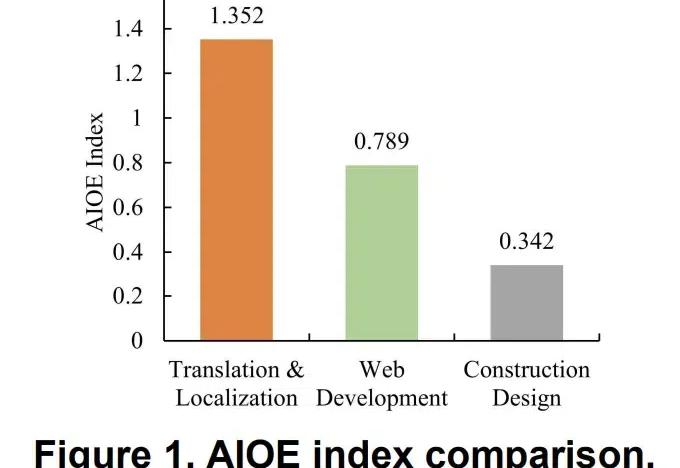
清华校友团队最新成果发现:写作、咨询、编程等相关自由职业最终可能被AI取代,而且更关键的是,AI能力一旦超过某个「拐点」,对就业市场的冲击将一发不可收拾。
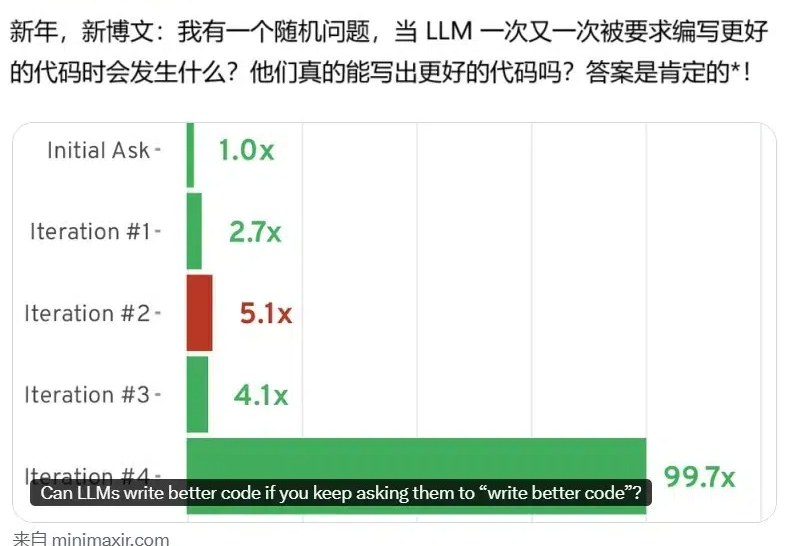
AI 的编程能力已经得到了证明,但还并不完美。近日,BuzzFeed 的资深数据科学家 Max Woolf 发现,如果通过提示词不断要求模型写更好的代码(write better code),AI 模型还真能写出更好的代码!

眼病诊疗,会迈上怎样的台阶? 用“手机看病”,这个听起来颇为科幻的场景,其实已经走进了现实。
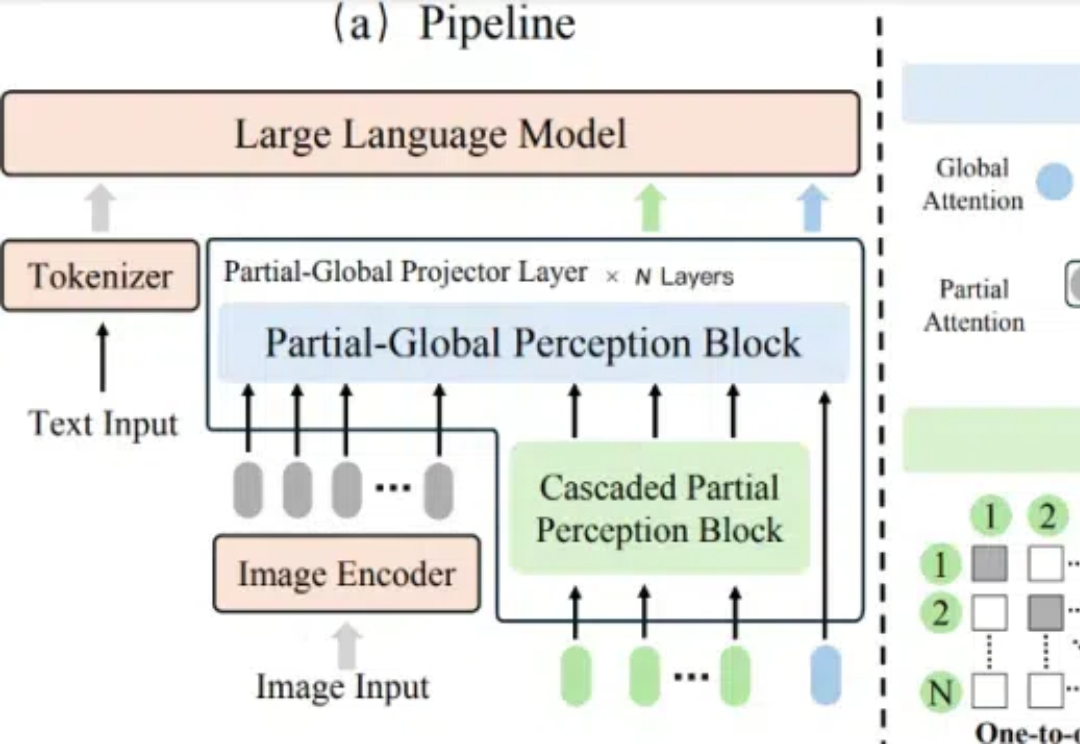
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。