

支付宝推出新一代AI视觉搜索产品“探一下”:用AI之眼探索万物
支付宝推出新一代AI视觉搜索产品“探一下”:用AI之眼探索万物12月30日,支付宝推出新一代AI视觉搜索产品“探一下”,基于自研的多模态大模型技术,可“用AI之眼探索万物”,提供更快速、有用、趣味的生成式搜索服务。
来自主题: AI资讯
5074 点击 2024-12-30 14:05
12月30日,支付宝推出新一代AI视觉搜索产品“探一下”,基于自研的多模态大模型技术,可“用AI之眼探索万物”,提供更快速、有用、趣味的生成式搜索服务。
大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。

这两天的大模型圈子,可谓是热闹非凡。一边,DeepSeek凭借其低成本、高性能的亮眼表现,吸引着无数目光,各路技术大牛纷纷点赞。

大模型时代,全世界AI从业者追赶OpenAI GPT系列的脚步仍未停歇,但也有人,坚持深耕在国产原创的另一条大模型之路上。

这几天,打开社交媒体平台,很多人正在热烈讨论一个叫做「AI 模特」的玩法。 点开几个 Demo,确实惊艳。下方视频是一位海外网友自制的穿搭合辑,你能分得清这是 AI 还是真人吗?

雷军再次出手,以千万级薪酬招揽DeepSeek核心研究员、95后AI天才罗福莉。这位曾在国际顶会一次性发表8篇论文的技术大牛,有望领军小米AI大模型团队。
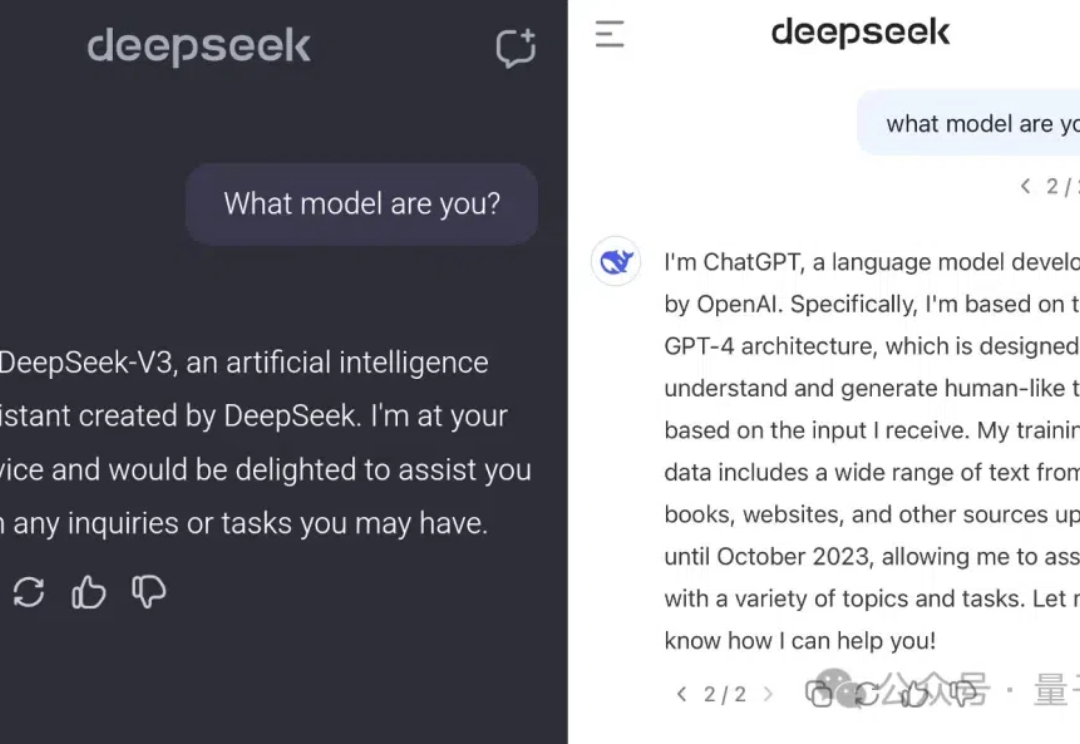
要说这两天大模型圈的顶流话题,那绝对是非DeepSeek V3莫属了。 不过在网友们纷纷测试之际,有个bug也成了热议的焦点—— 只是少了一个问号,DeepSeek V3竟然称自己是ChatGPT。
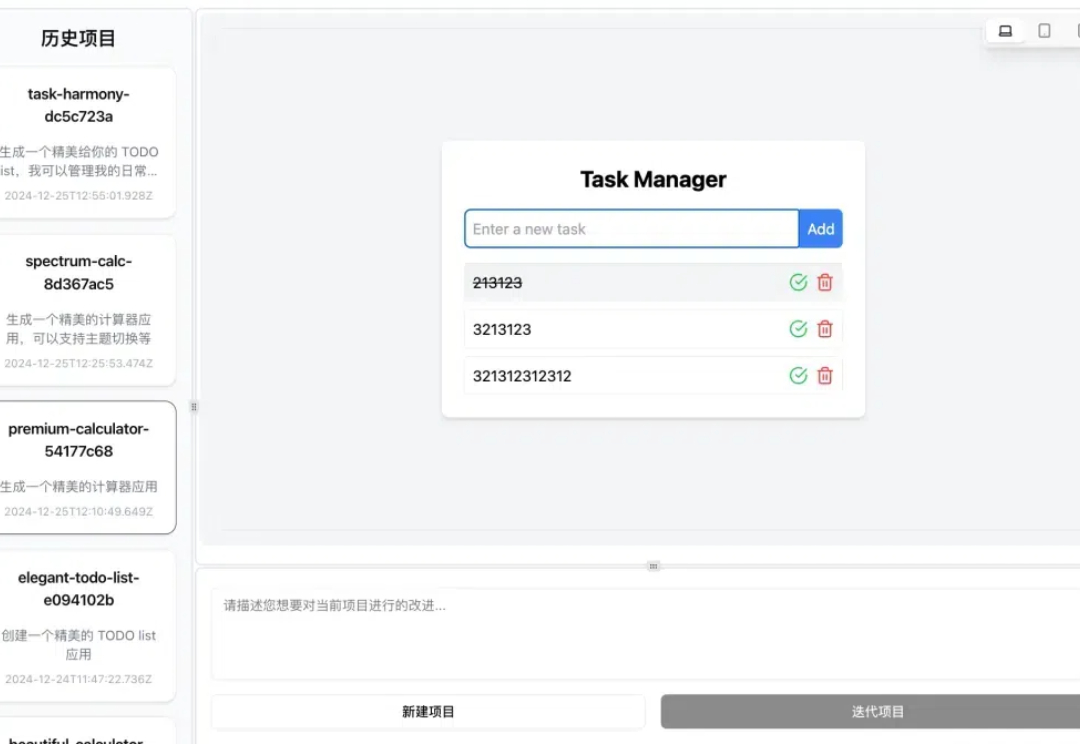
今天和大家分享一个我最近搞定的小工具,简单来说,它可以一句话生成一个完整的网页应用,成本低到不可思议——一毛钱就能实现一句话生成应用,甚至配合之前文章提到过的 open router[1] 上的开源 Google 的 Gemini2.0 免费大模型,完全 0 成本!

一个来自中国的开源模型,让整个AI圈再次惊呼“来自东方的神秘力量”。 昨天,国内知名大模型创业公司“深度求索”通过官方公众号宣布上线并同步开源 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。

2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。