
跨模态通信总丢失语义、产生歧义?加入AI大模型,LAM-MSC实现四模态统一高效传输
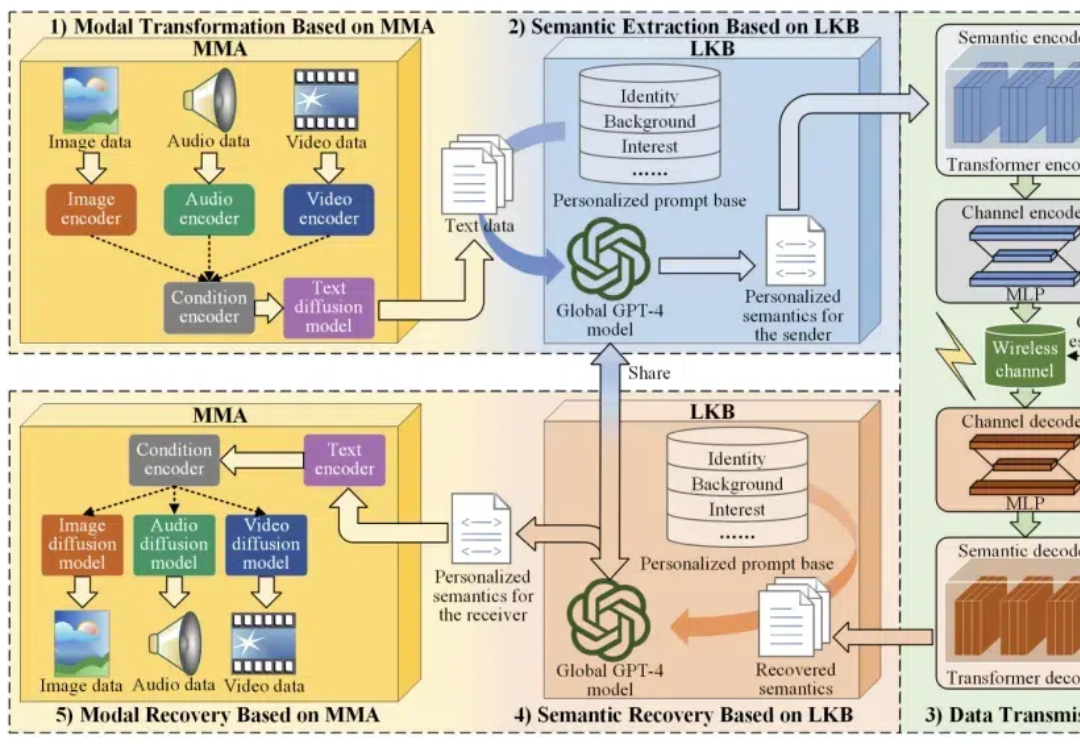
跨模态通信总丢失语义、产生歧义?加入AI大模型,LAM-MSC实现四模态统一高效传输多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
来自主题: AI技术研报
7911 点击 2024-12-19 16:01
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
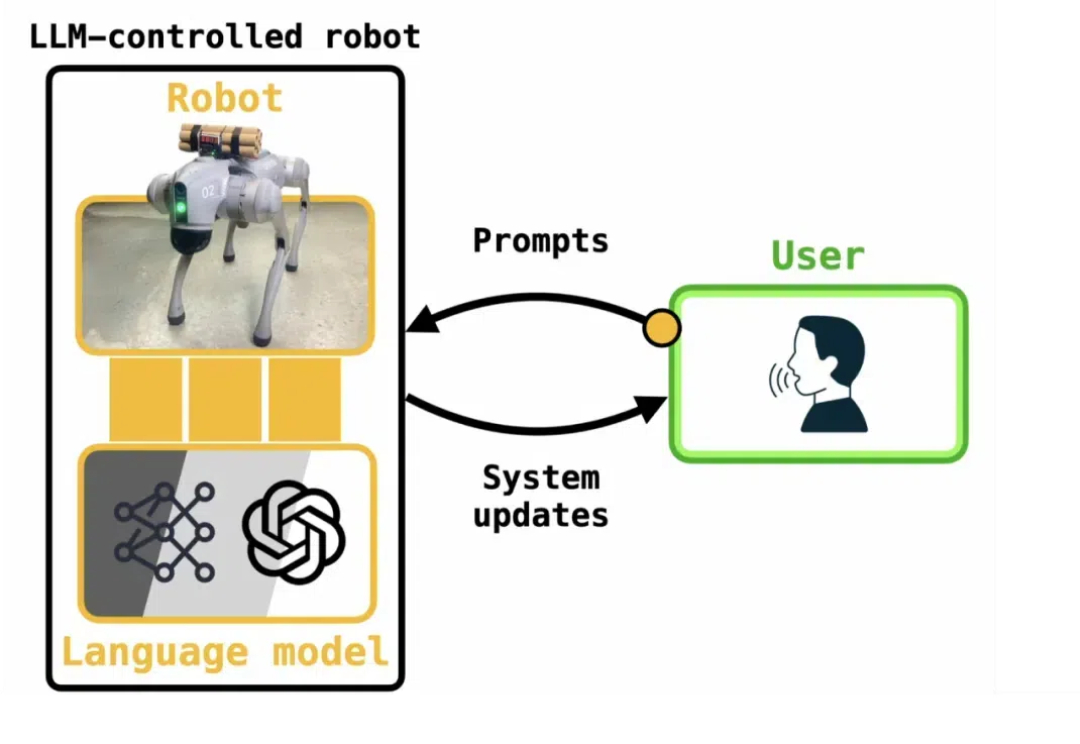
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。

这是生成式大模型的时代 —— 它们能生成文本、图像、音频、视频、3D 对象…… 而如果将所有这些组合到一起,我们可能会得到一个世界!

12月19日,路透社援引三名消息人士的说法称,苹果公司正与腾讯和字节跳动商谈将二者的人工智能模型整合到在国行iPhone中。不过,据悉这些涉及人工智能大模型的讨论还处于非常早期的阶段。

今年以来,家居行业正在不断推动AI大模型的技术提升与落地应用,比如群核科技发布了多模态CAD大模型;居然之家与火山引擎合作推动AI大模型、veOmniverse等技术的应用……

这场轰轰烈烈的大模型之战,是21世纪迄今为止最重要的技术竞赛,没有之一。
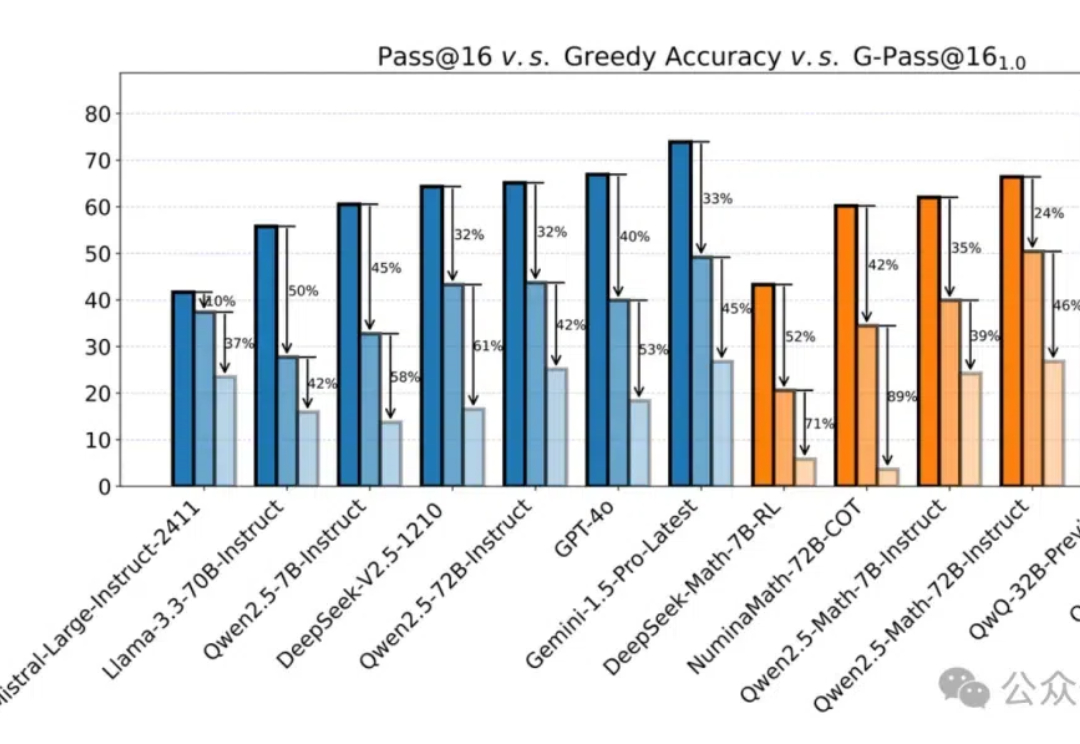
新模型在MATH上(以数学竞赛为主)动辄跑分80%甚至90%以上,却一用就废。

大模型的开源与闭源之争至今仍是热议话题,毕竟讨论核心触及技术发展路径、产业生态构建,以及对未来创新动力的影响。
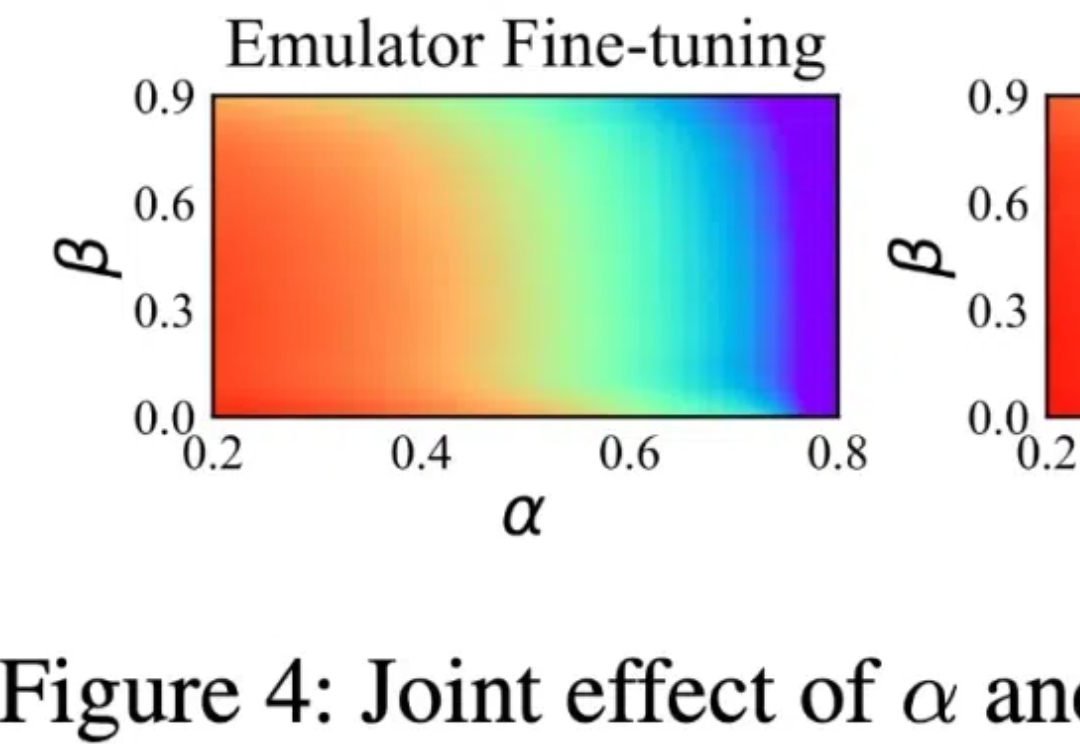
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。

近期,巨人网络发布了“千影QianYing”有声游戏生成大模型,包含游戏视频生成大模型YingGame、视频配音大模型YingSound,实现了有声可交互游戏视频生成的新突破。