

谷歌“狙击”OpenAI,发布新一代大模型!主打Agent+多模态
谷歌“狙击”OpenAI,发布新一代大模型!主打Agent+多模态继量子芯片之后,谷歌又来抢“OpenAI双12直播”的流量了! 就在刚刚,谷歌新一代大模型Gemini 2.0突然登场,再次由谷歌CEO皮猜亲自官宣。
来自主题: AI资讯
7233 点击 2024-12-12 09:14
继量子芯片之后,谷歌又来抢“OpenAI双12直播”的流量了! 就在刚刚,谷歌新一代大模型Gemini 2.0突然登场,再次由谷歌CEO皮猜亲自官宣。

多模态大模型在听觉上,居然也出现了「9.11>9.8」的现象,音量大小这种简单问题都识别不了!港中文、斯坦福等大学联合发布的AV-Odyssey基准测试,包含26个视听任务,覆盖了7种声音属性,跨越了10个不同领域,确保测试的深度和广度。

本期我们有幸邀请到生数科技工程副总裁(VP)陈鑫与百度智能云AI计算部副总经理兰宇,深度解析Vidu这款视频大模型从发布到在行业内爆火的背后故事。

在数字化浪潮中,大模型已成为推动社会进步和商业创新的关键力量。特别是在AI Agent领域,我们见证了技术从概念到实践的飞跃,它们不仅改变了我们的工作方式,也重塑了我们对智能技术的期待。《2024中国AI Agent最佳实践榜单》旨在梳理和展示企业在AI Agent领域的杰出实践,表彰那些在技术应用、创新突破和行业变革中做出突出贡献的案例。
过去一年,基于高效大模型和端侧AI的商业化布局和业务推进,面壁智能有着较为迅速的行业落地进展。
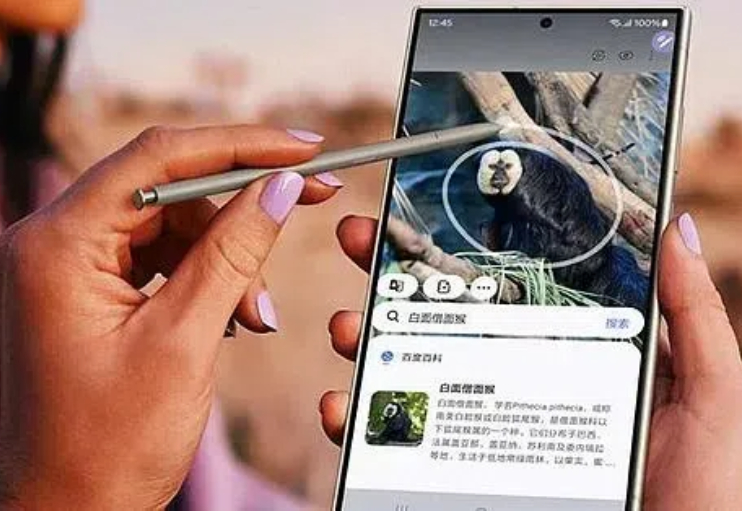
Sora 终于来了! 只要是 ChatGPT Plus/Pro 用户,直接就能用上。 至于效果 ...... 看完官方放出的 demo,网友大呼:不太行 !
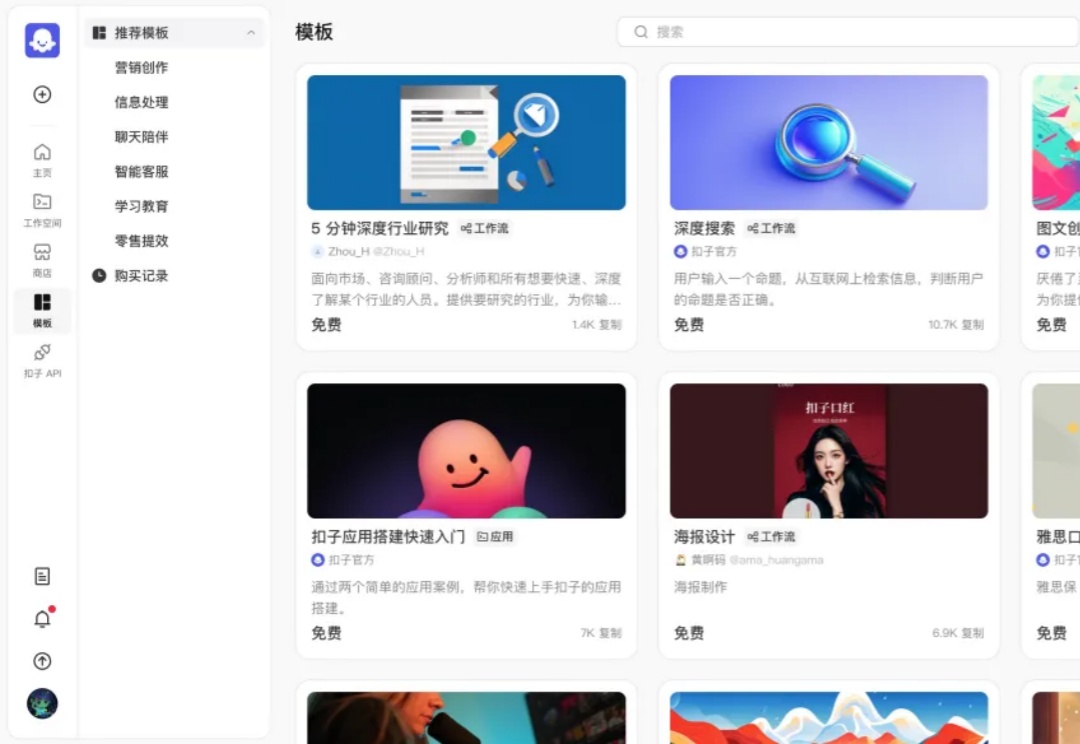
前一段时间,我看到有人问:感觉 AI 大模型热度下降了,人们是不是去 AI 祛魅了?我的看法是这样的,不是 AI 失去了魅力,而是大多数人不会使用,原因就出现在聊天对话框这样的 LUI 形式上。

大模型的牌局,国内企业正在找到自己的节奏感。Sora,自2月16日OpenAI发布后一直被吐槽是“技术期货”,终于在12月10日,正式版Sora露面了,可以生成最高 1080p 分辨率、最长 20 秒的视频。
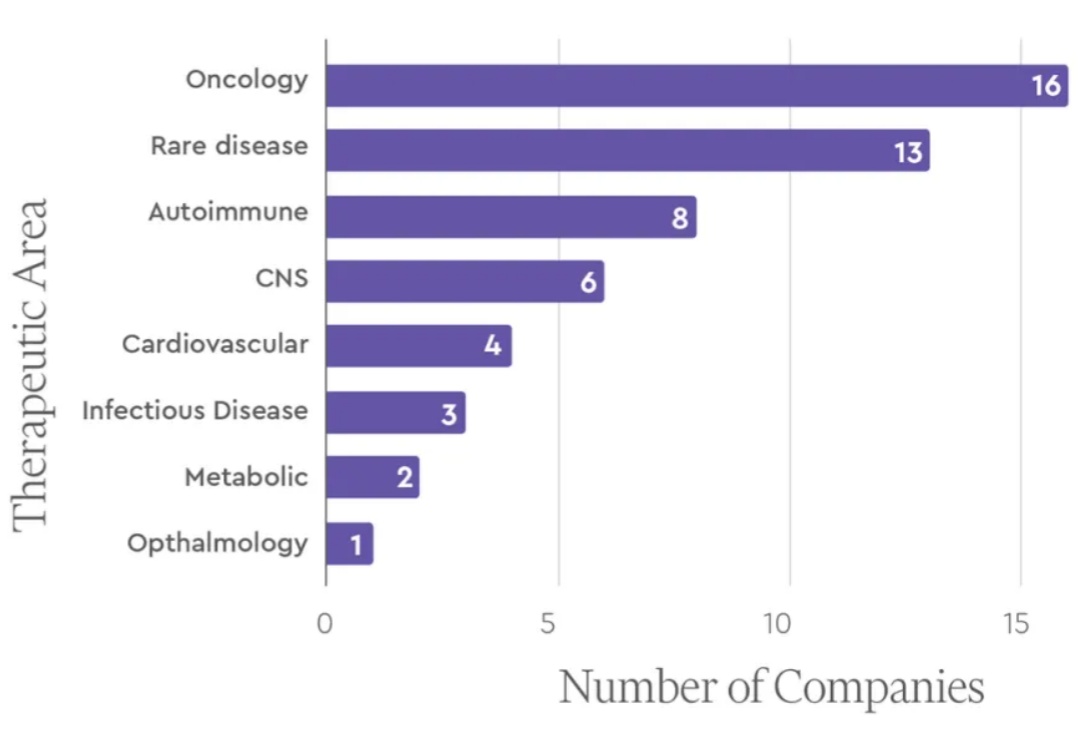
AI for Science 是目前大模型落地的热门场景之一。

中科闻歌的产品与技术已广泛应用于近千家客户,是业内为数不多的收入成规模化的AI公司之一。