

狂奔两周年,激辩AI大模型“撞墙”
狂奔两周年,激辩AI大模型“撞墙”OpenAI奥特曼前天发了条神神秘秘的推文,“there is no wall”。
来自主题: AI资讯
6753 点击 2024-11-15 15:44
OpenAI奥特曼前天发了条神神秘秘的推文,“there is no wall”。
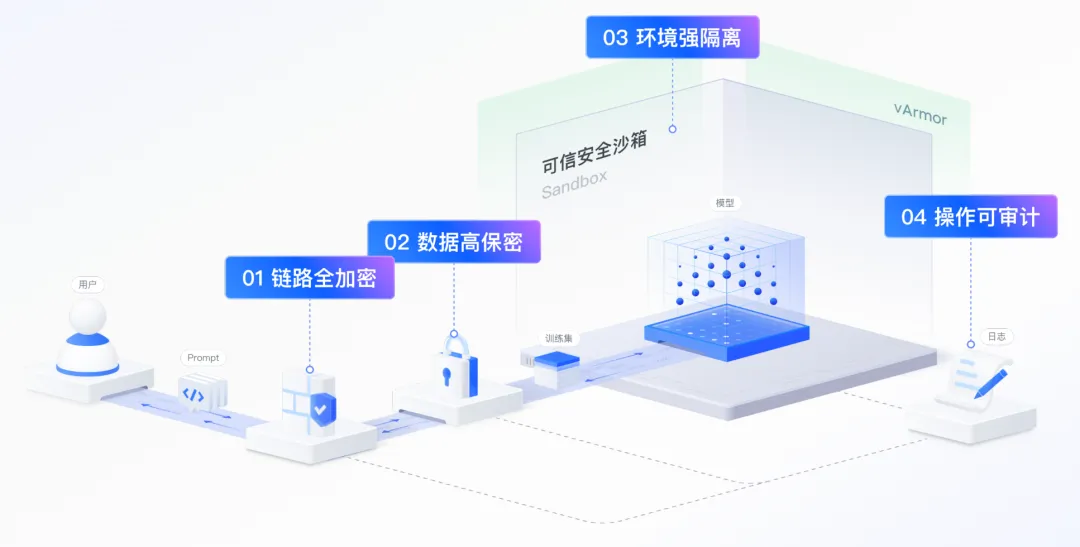
2024 年,AI 大模型从「以分计价」跨入「以厘计价」的时代。

2024年下半年,AI行业的人才流动呈现出戏剧性的转折:从科技巨头出走创业后,如今又选择回流大厂。

破解基因组的奥秘一直是生物科学的前沿挑战,如何让人工智能(AI)读懂 DNA 的复杂信息,并用它来设计和操控生命的“程序代码”?
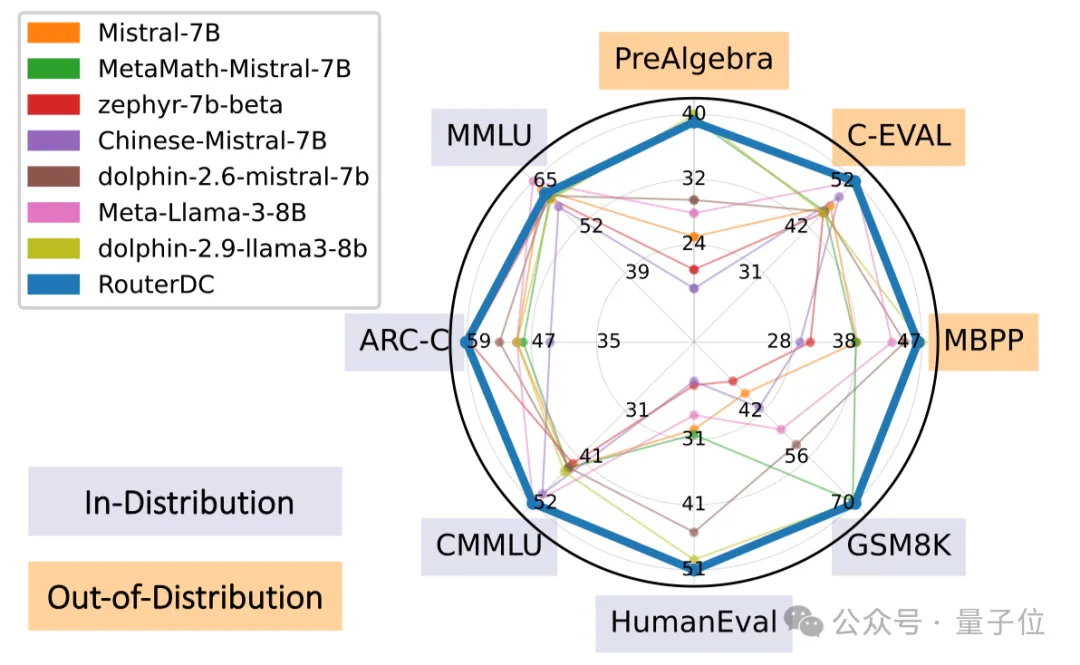
高效组合多个大模型“取长补短”新思路,被顶会NeurIPS 2024接收。
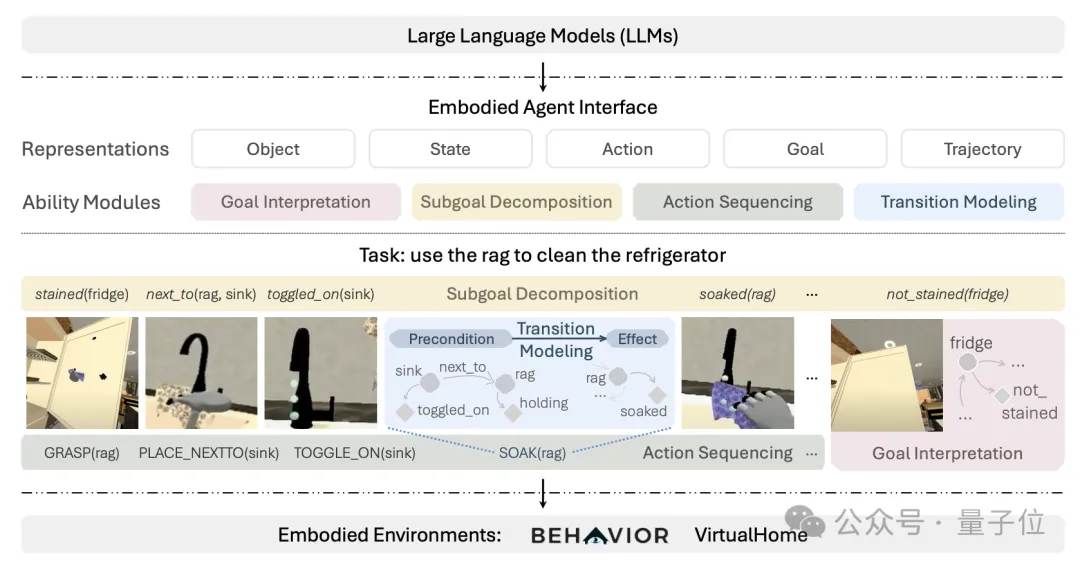
大模型的具身智能决策能力,终于有系统的通用评估基准了。

大模型的发展呈现出追风逐日般的速度,但与之相伴的安全问题,也是频频被曝光。

大模型狂热继续,但今天依然沿着一条路或者一个路线图前进的公司或产品却并不多了,有的“模型”公司做着做着没模型了,有的从情感到生产力再到视觉做了个遍,有的干脆从c转到b,也不再批评过往b端必做的项目制了。

随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。

大模型的下一个风口,就在眼前了:使用百度文心智能体,有人的单次转化最高收入已经达到10万元!无论是9岁小学生,38岁失业打工人,还是51岁退休阿姨,都能轻松玩转。文心智能体,将为千行百业注入AI新动力。