

AI翻译界杀手诞生!阿里国际翻译大模型吊打谷歌和GPT-4
AI翻译界杀手诞生!阿里国际翻译大模型吊打谷歌和GPT-4AI翻译,全球大厂都卷疯了!但「绿就是白」「光腿神」这类翻译却让人啼笑皆非。就在刚刚,阿里国际发布首个商用翻译大模型,电商出海神器真来了!
来自主题: AI资讯
5695 点击 2024-10-16 14:47
AI翻译,全球大厂都卷疯了!但「绿就是白」「光腿神」这类翻译却让人啼笑皆非。就在刚刚,阿里国际发布首个商用翻译大模型,电商出海神器真来了!

国产大模型首次在公开榜单上超过GPT-4o! 就在刚刚,“大模型六小强”之一的零一万物正式对外发布新旗舰模型——Yi-Lightning(闪电)。

AI大模型风头虽盛,在资本推波助澜下,使得融资一轮高过一轮,这种投机行为也助推AI大模型独角兽存在巨大泡沫成份。
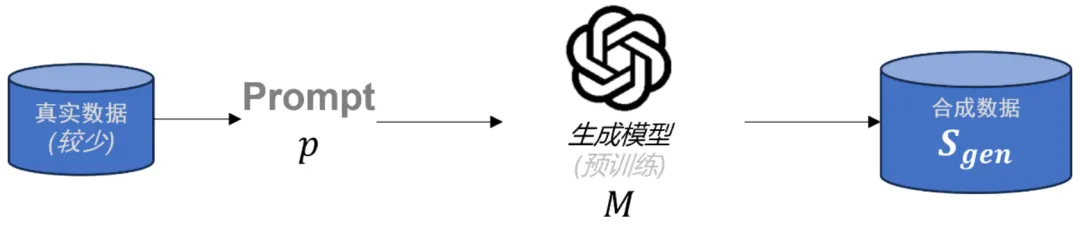
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

越大的行业,创新的机会就越多的,能够解决的问题也越多。

随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。

别信忽悠,信实测。

LightRAG通过双层检索范式和基于图的索引策略提高了信息检索的全面性和效率,同时具备对新数据快速适应的能力。在多个数据集上的实验表明,LightRAG在检索准确性和响应多样性方面均优于现有的基线模型,并且在资源消耗和动态环境适应性方面表现更优,使其在实际应用中更为有效和经济。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。