

COLM 24 | 从正确中学习?大模型的自我纠正新视角
COLM 24 | 从正确中学习?大模型的自我纠正新视角大型语言模型(LLMs)虽然进展很快,很强大,但是它们仍然存在会产生幻觉、生成有害内容和不遵守人类指令等问题。一种流行的解决方案就是基于【自我纠正】,大概就是看自己输出的结果,自己反思一下有没有错,如果有错就自己改正。目前自己纠正还是比较关注于让大模型从错误中进行学习。
来自主题: AI技术研报
9081 点击 2024-09-17 21:26
大型语言模型(LLMs)虽然进展很快,很强大,但是它们仍然存在会产生幻觉、生成有害内容和不遵守人类指令等问题。一种流行的解决方案就是基于【自我纠正】,大概就是看自己输出的结果,自己反思一下有没有错,如果有错就自己改正。目前自己纠正还是比较关注于让大模型从错误中进行学习。
北京时间 9 月 13 日午夜,OpenAI 发布了推理性能强大的 ο1 系列模型。之后,各路研究者一直在尝试挖掘 ο1 卓越性能背后的技术并尝试复现它。当然,OpenAI 也想了一些方法来抑制窥探,比如有多名用户声称曾试图诱导 ο1 模型公布其思维过程,然后收到了 OpenAI 的封号威胁。
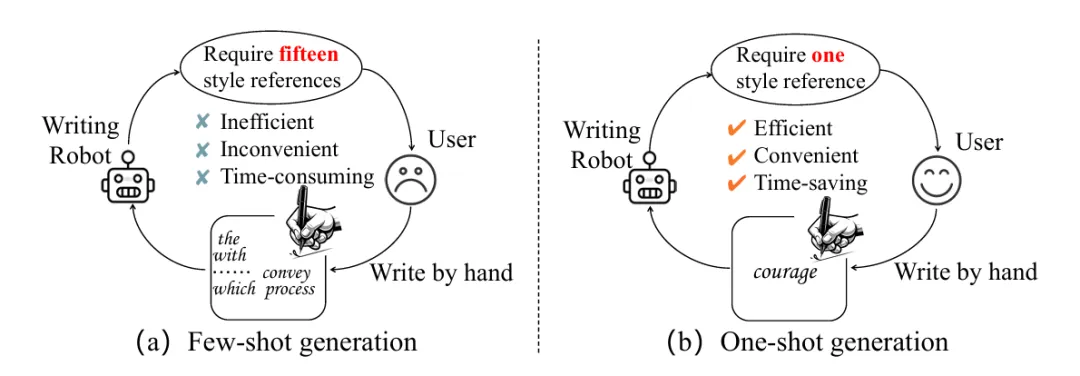
来自华南理工大学、新加坡国立大学、昆仑万维以及琶洲实验室的研究者们提出一种新的风格化手写文字生成方法,仅需提供单张参考样本即可临摹用户的书写风格,支持英文,中文和日文三种文字的临摹。
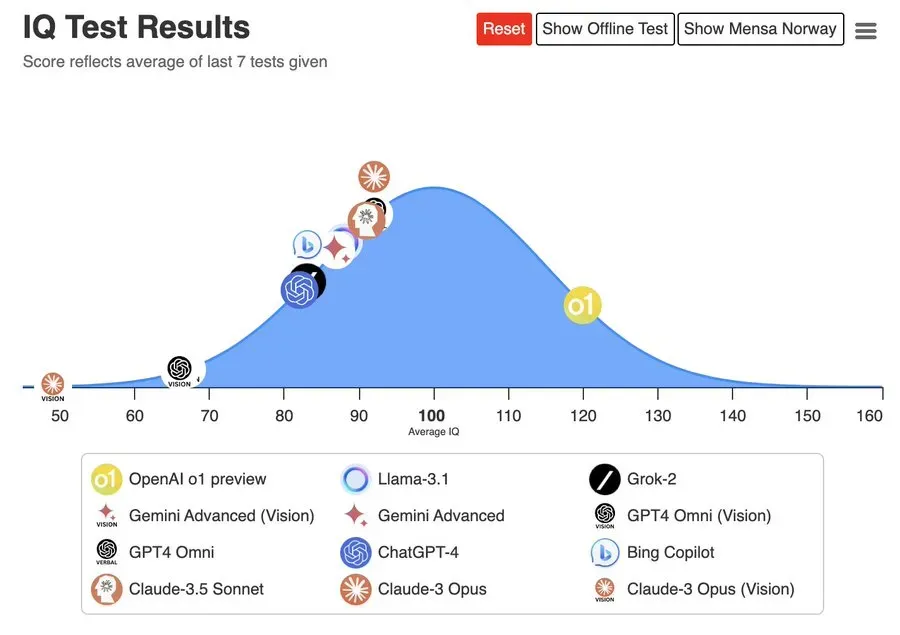
全网 OpenAI o1 的测试基本跑完,大家基本认可这是一个独立思考智商超高的模型,智商测试120,高考数学全对。

以前最宝贵的资源是黄金,现在最宝贵的资源是算力。
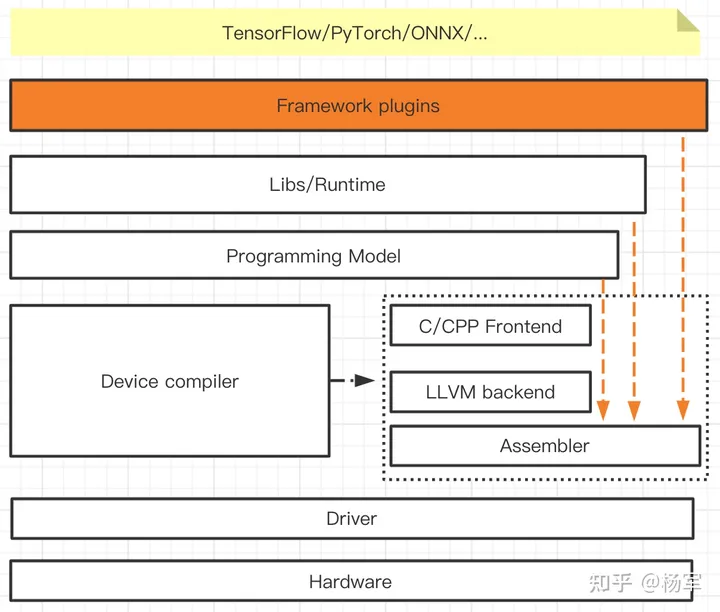
AI框架算子层级的思考其实源于周五参加WAIC上组织的AI编译相关的闭门讨论的内容,观点有不少来源于现场讨论的朋友们,因为对这个主题感兴趣,我又结合自己的理解做了一些梳理。

阴谋论的“兔子洞”,被AI破解了!
大模型下半场,新范式开启?

进万企,解难题,优环境,促发展。
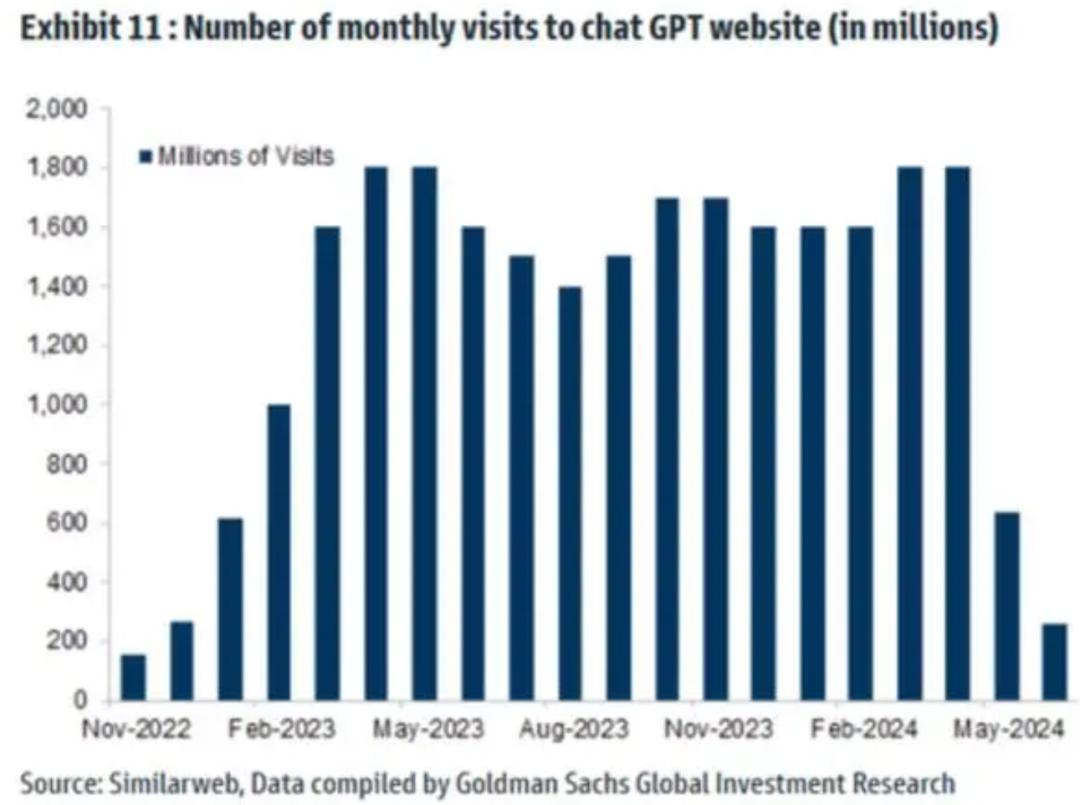
进入行业深水区,水本就会变冷。