

红杉美国合伙人 David Cahn:AI 的核心三要素——Servers, Steel and Power
红杉美国合伙人 David Cahn:AI 的核心三要素——Servers, Steel and Power如果我们今天要谈论科技或风险投资,那么接下来的话题只会让我们想到 AI.
来自主题: AI资讯
6649 点击 2024-08-10 17:38
如果我们今天要谈论科技或风险投资,那么接下来的话题只会让我们想到 AI.
前段时间冲上热搜的问题「9.11比9.9大吗?」,让几乎所有LLM集体翻车。看似热度已过,但AI界大佬Andrej Karpathy却从中看出了当前大模型技术的本质缺陷,以及未来的潜在改进方向。

有CPU就能跑大模型,性能甚至超过NPU/GPU!
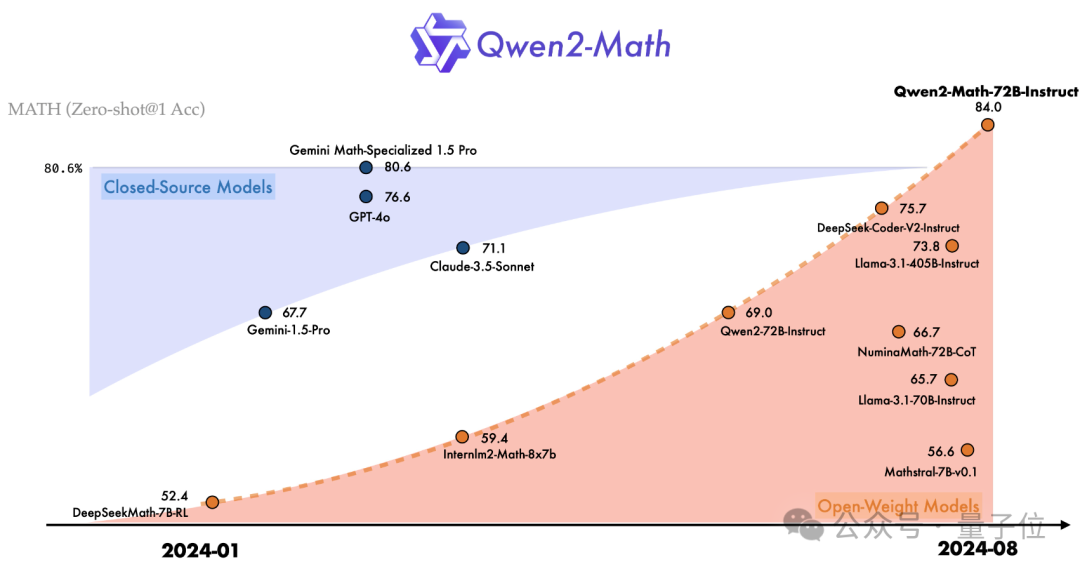
最强数学大模型,现在易主!

GPT-4o的怪癖暴露了,还是被官方公开的!

GPT-5 大模型?不要太着急。

RLHF 与 RL 到底能不能归属为一类,看来大家还是有不一样的看法。

但可能打不过公园里的老大爷?
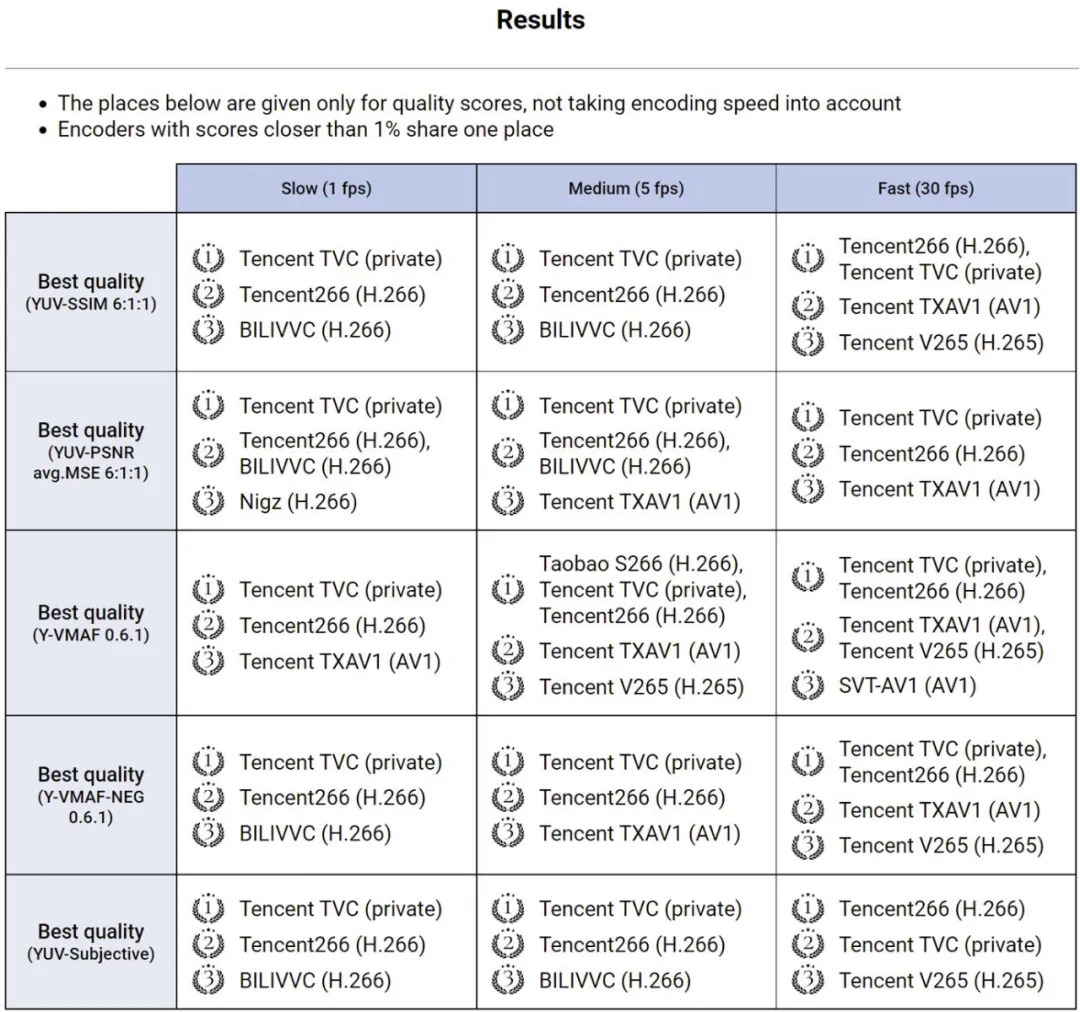
今日获悉,由莫斯科国立大学举办的 MSU 世界视频编码器大赛结果揭晓。在全部参赛编码器中,腾讯编码器包揽所有 15 项指标的全部第一,再次斩获全场最佳。

专注于计算机图形学的全球学术顶会 SIGGRAPH,正在出现新的趋势。