

居家办公享时薪40美元!27岁华裔CEO招聘博士训练AI数据标注
居家办公享时薪40美元!27岁华裔CEO招聘博士训练AI数据标注市值140亿美元的初创公司Scale AI正在招聘博士训练LLM,用人成本的升高让该公司的毛利率在2023年有所下降,但创始人Alexandr Wang预计今年营收将增加两倍,突破十亿美元。
来自主题: AI资讯
11757 点击 2024-07-07 16:58
市值140亿美元的初创公司Scale AI正在招聘博士训练LLM,用人成本的升高让该公司的毛利率在2023年有所下降,但创始人Alexandr Wang预计今年营收将增加两倍,突破十亿美元。
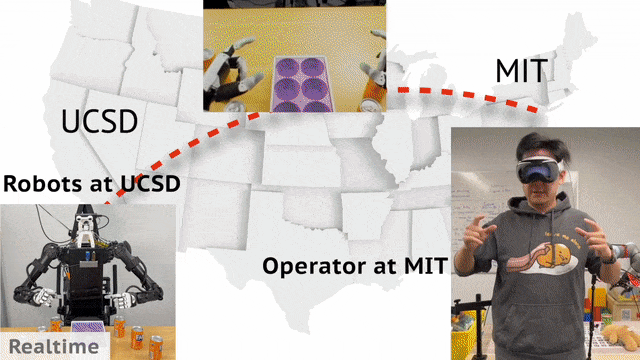
现实中,机器人收据收集可以通过远程操控实现。来自UCSD、MIT的华人团队开发了一个通用框架Open-TeleVision,可以让你身临其境操作机器人,即便相隔3000英里之外。

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力

今年是 AI 视频生成爆发的元年,以 Sora 为代表的算法模型和产品应用不断涌现。短短几个月内,我们目睹了几十种视频生成工具的问世,基于 AI 的视频创作方式开始流行起来。
大模型产业发展,需要可信中立的数据深加工平台,如何填补空白?
海明威的《太阳照常升起》中,迈克·坎贝尔说出了那个简短的名言:“逐渐地,然后突然地”( Gradually,and then suddenly)。

两分钟端到端从需求到应用,WAIC上这个国产开发神器火了!
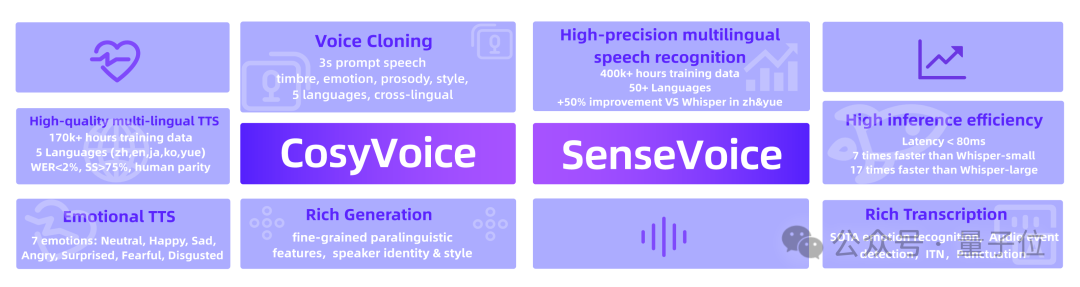
OpenAI迟迟不上线GPT-4o语音助手,其它音频生成大模型成果倒是一波接着一波发布,关键还是开源的。
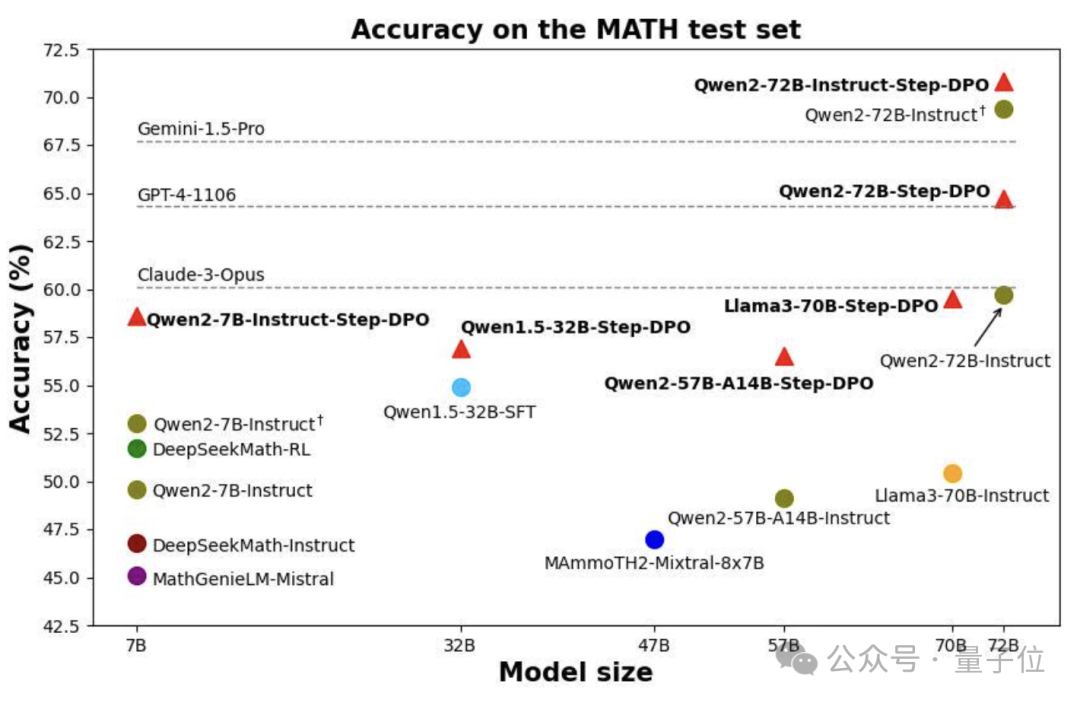
只要10k数据,就能让大模型的数学成绩增长5.6%。

AIGC时代,视频创作这事儿真的不一样了。