

「代理人战争」!微软、OpenAI 、谷歌、Meta用AI Agent疯狂搞钱
「代理人战争」!微软、OpenAI 、谷歌、Meta用AI Agent疯狂搞钱大模型发展至今早已火成了一个「概念」。
来自主题: AI技术研报
9527 点击 2024-05-05 19:55
大模型发展至今早已火成了一个「概念」。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。

随着 Llama 3 发布,未来大模型的参数量已飙升至惊人的 4000 亿。尽管每周几乎都有一个声称性能超强的大模型出来炸场,但 AI 应用还在等待属于它们的「ChatGPT 时刻」。其中,AI 智能体无疑是最被看好的赛道。

资本市场即将决出下一阶段人工智能受益者。一年多来,人工智能一直是投资者关注的焦点,为这一新周期构建硬件和软件的公司享受着出色的股票回报。接下来,一些非科技企业将从人工智能中受益,他们通过AI工具提高效率和生产力。

没想到,在大模型时代,知名「AI 教母」李飞飞也要「创业」了,并完成了种子轮融资。

今年 1 月份,2024 年度 IEEE 冯诺伊曼奖项结果正式公布,斯坦福大学语言学和计算机科学教授、AI 学者克里斯托弗・曼宁(Christopher Manning)获奖。

近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。
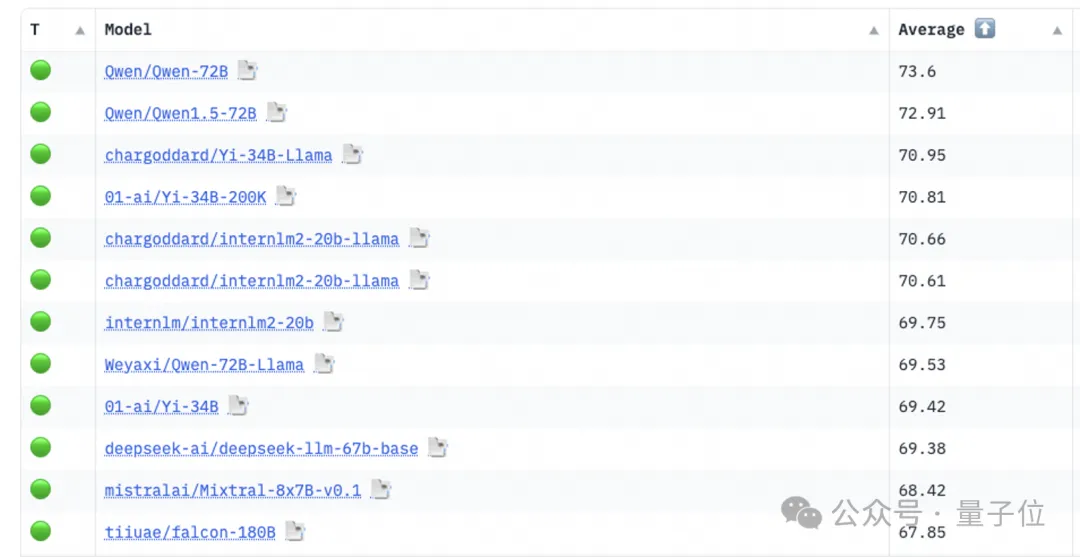
在过去一年中,通义千问系列模型持续开源。

“预测下一个token”被认为是大模型的基本范式,一次预测多个tokens又会怎样?

全球AIGC应用浪潮下,怎样将大模型产品以一种更贴近消费者的形式融入生产力工具?