

谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择JAX在最近的基准测试中的性能已经不声不响地超过了Pytorch和TensorFlow,也许未来会有更多的大模型诞生在这个平台上。谷歌在背后的默默付出终于得到了回报。
来自主题: AI资讯
7737 点击 2024-04-01 19:01
JAX在最近的基准测试中的性能已经不声不响地超过了Pytorch和TensorFlow,也许未来会有更多的大模型诞生在这个平台上。谷歌在背后的默默付出终于得到了回报。
LLM战场的新玩家,一出手就是王炸!信仰Scaling Law的阶跃星辰,一口气带来了Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型,以及Step-2万亿参数MoE语言大模型的预览版。而阶跃星辰之旅,终点就是AGI。

3 月 28 日,云天励飞举办 AI 大模型产品发布会,发布“深目”AI 模盒,同时宣布自研大模型“云天天书-2.0-68B”版本免费向合作伙伴开放。

澜舟科技官宣:孟子3-13B大模型正式开源!这一主打高性价比的轻量化大模型,面向学术研究完全开放,并支持免费商用。
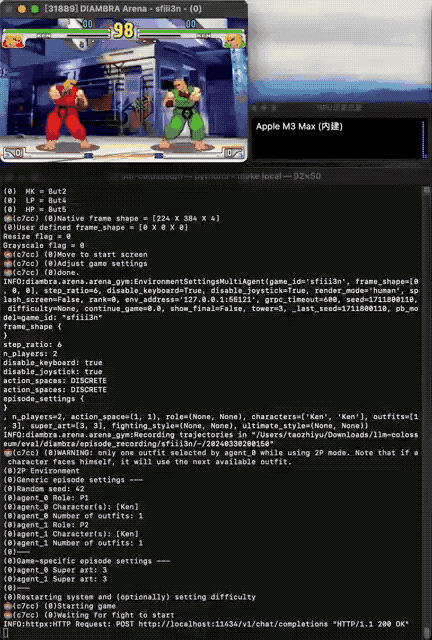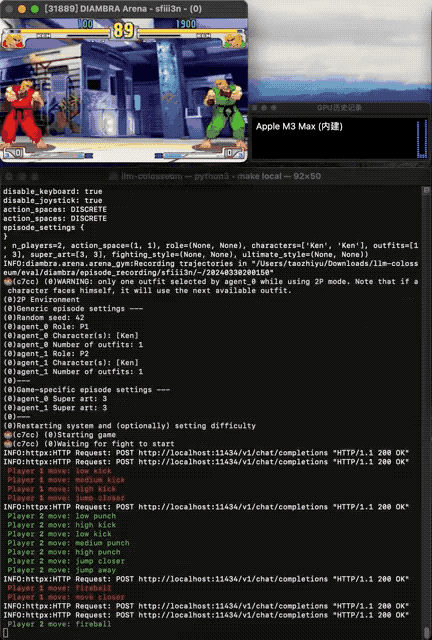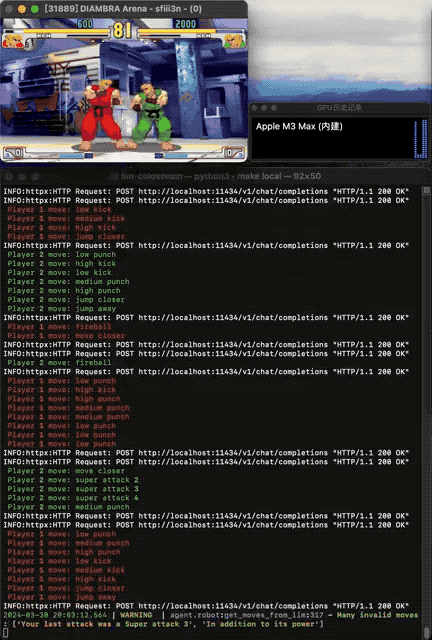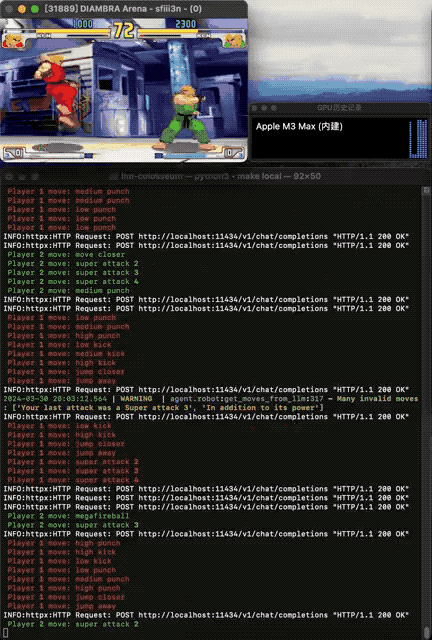
让大模型直接操纵格斗游戏《街霸》里的角色,捉对PK,谁更能打?GitHub上一种你没有见过的船新Benchmark火了。

国内基础大模型创业公司,最后一位强实力选手终于正式来到台前。它就是微软前全球副总裁姜大昕所创办的阶跃星辰。

随着生成模型(如 ChatGPT、扩散模型)飞速发展,一方面,生成数据质量越来越高,到了以假乱真的程度;另一方面,随着模型越来越大,也使得人类世界的真实数据即将枯竭。

2022 年底,随着 ChatGPT 的爆火,人类正式进入了大模型时代。然而,训练大模型需要的时空消耗依然居高不下,给大模型的普及和发展带来了巨大困难。面对这一挑战,原先在计算机视觉领域流行的 LoRA 技术成功转型大模型 [1][2],带来了接近 2 倍的时间加速和理论最高 8 倍的空间压缩,将微调技术带进千家万户。
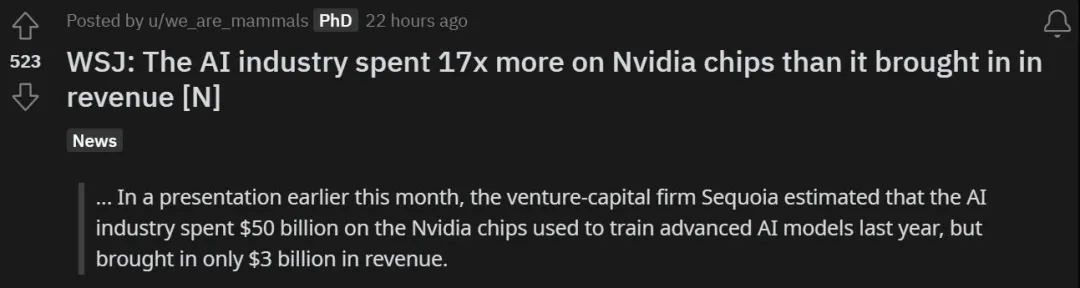
搞 AI 大模型,实在太烧钱了。我们知道,如今的生成式 AI 有很大一部分是资本游戏,科技巨头利用自身强大的算力和数据占据领先位置,并正在使用先进 GPU 的并行算力将其推广落地。这么做的代价是什么?最近《华尔街日报》一篇有关明星创业公司的报道里给出了答案:投入是产出的 17 倍。

攀登 Scaling Law,打造万亿参数大模型,前微软 NLP 大牛姜大昕披露创业路线图。