

微软亚研院新作:让大模型一口气调用数百万个API!
微软亚研院新作:让大模型一口气调用数百万个API!近年来,人工智能发展迅速,尤其是像ChatGPT这样的基础大模型,在对话、上下文理解和代码生成等方面表现出色,能够为多种任务提供解决方案。
来自主题: AI资讯
8620 点击 2024-03-29 11:26
近年来,人工智能发展迅速,尤其是像ChatGPT这样的基础大模型,在对话、上下文理解和代码生成等方面表现出色,能够为多种任务提供解决方案。
好家伙,现在随便打开一个大模型应用,支持的文本都有那————么长。

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。

扩散模型凭借其在图像生成方面的出色表现,开启了生成式模型的新纪元。诸如 Stable Diffusion,DALLE,Imagen,SORA 等大模型如雨后春笋般涌现,进一步丰富了生成式 AI 的应用前景。然而,当前的扩散模型在理论上并非完美,鲜有研究关注到采样时间端点处未定义的奇点问题。此外,奇点问题在应用中导致的平均灰度等影响生成图像质量的问题也一直未得到解决。

今年升级的重点在于引入了多模态大模型能力。

这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。

AI 时代,在大模型能力还在进化、还在苦苦寻找 PMF 之前,创业者之间的交流和共识似乎变得更为重要。一次成功的尝试,或者是失败的反思;或者是最近的创业新方向和新收获;或者是对于某个垂直领域的新观察。
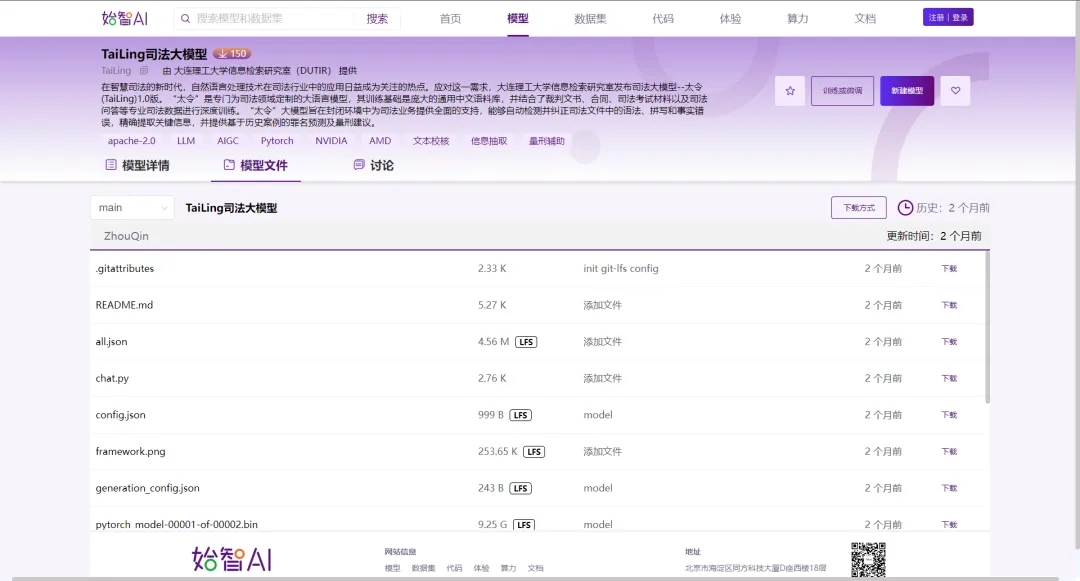
大连理工大学信息检索研究室在始智AI wisemodel.cn开源社区发布了司法大模型--太令(TaiLing)1.0版,“太令”是专门为司法领域定制的大语言模型,其训练基础是庞大的通用中文语料库,并结合了裁判文书、合同、司法考试材料以及司法问答等专业司法数据进行深度训练。

上下文长度真的能形成护城河吗?

除了没有成熟商业模式,Stability AI更缺乏能力证明他们可以继续开发顶尖大模型。