
打破代码大模型训练瓶颈:微软&剑桥&普林推出MicroCoder,算法、数据、框架、训练经验全面升级
打破代码大模型训练瓶颈:微软&剑桥&普林推出MicroCoder,算法、数据、框架、训练经验全面升级新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
来自主题: AI技术研报
10640 点击 2026-03-30 09:29
 搜索
搜索
新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。

国产大模型阵营再添硬核选手,智谱开放平台GLM5.1正式上线,推理、代码、智能体能力拉满,还为新用户准备了2000万Tokens免费体验包,覆盖多模型使用额度,有效期3个月。不管是日常编程开发、智能体搭建,还是多模态内容创作,这个免费额度都能轻松拿捏,新手也能零门槛上手,这波福利可别错过。

在会上,昆仑万维旗下天工 AI 重磅发布了全新 AI 游戏世界模型 Matrix-Game 3.0、AI 视频大模型 SkyReels V4 和 AI 音乐大模型 Mureka V9,在继续强化 AIGC 理解与生成能力的同时,进一步推进 AI 对物理世界的建模与仿真。
刚刚,《财富》独家爆出——由于一次罕见的「人为配置」错误,最强大模型「Claude Mythos」绝密细节公之于众。Claude Mythos代号「Capybara」,代表最高「层级」,是一款具有划时代意义的全新模型。
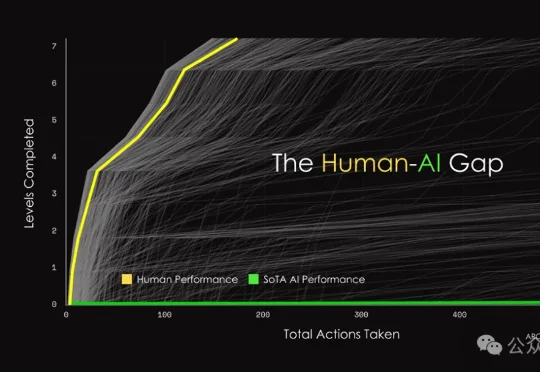
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
昨日晚间,前阿里千问大模型负责人林俊旸(Junyang Lin)在社交平台X上发表了《从“推理式思考”到“智能体式思考”(From "Reasoning" Thinking to "Agentic" Thinking)》的长文,引起AI技术产业圈关注。
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
大模型开发者常面临一个两难选择:要速度,还是省显存?
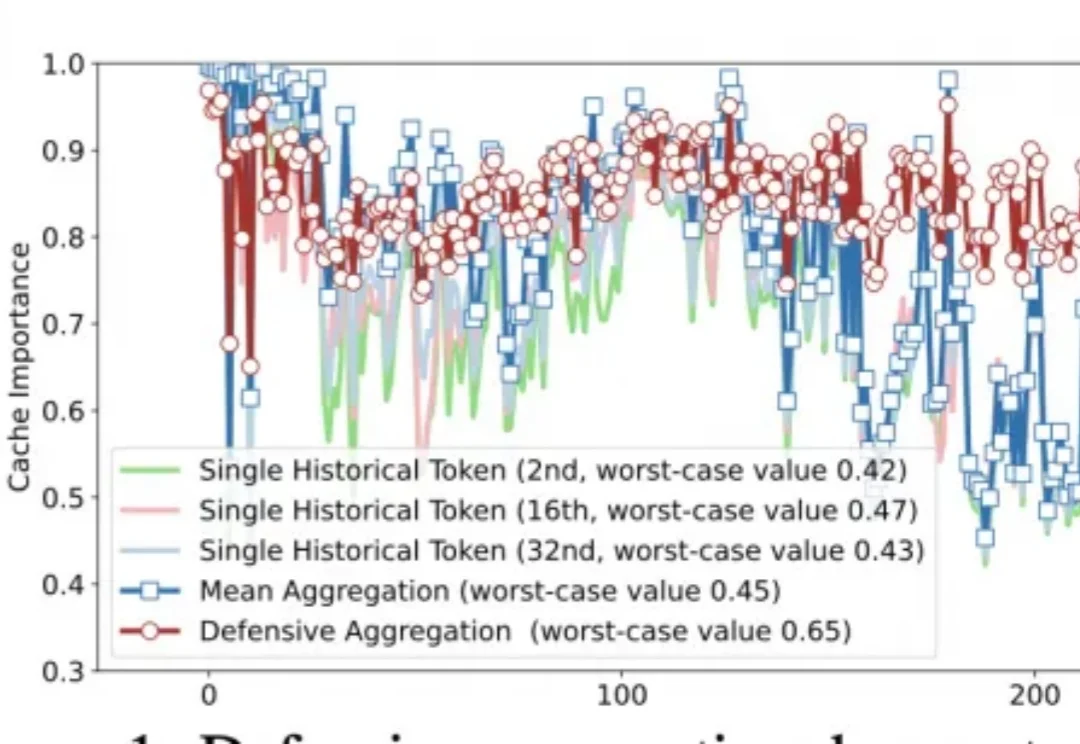
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。