

清华NLP组发布InfLLM:无需额外训练,「1024K超长上下文」100%召回!
清华NLP组发布InfLLM:无需额外训练,「1024K超长上下文」100%召回!挖掘大模型固有的长文本理解能力,InfLLM在没有引入额外训练的情况下,利用一个外部记忆模块存储超长上下文信息,实现了上下文长度的扩展。
来自主题: AI技术研报
6015 点击 2024-03-11 17:31
挖掘大模型固有的长文本理解能力,InfLLM在没有引入额外训练的情况下,利用一个外部记忆模块存储超长上下文信息,实现了上下文长度的扩展。

近年来,大语言模型(LLMs)由于其通用的问题处理能力而引起了大量的关注。现有研究表明,适当的提示设计(prompt enginerring),例如思维链(Chain-of-Thoughts),可以解锁 LLM 在不同领域的强大能力。

近期,来自华为诺亚方舟实验室的研究者提出了 DenseSSM,用于增强 SSM 中各层间隐藏信息的流动。通过将浅层隐藏状态有选择地整合到深层中,DenseSSM 保留了对最终输出至关重要的精细信息。
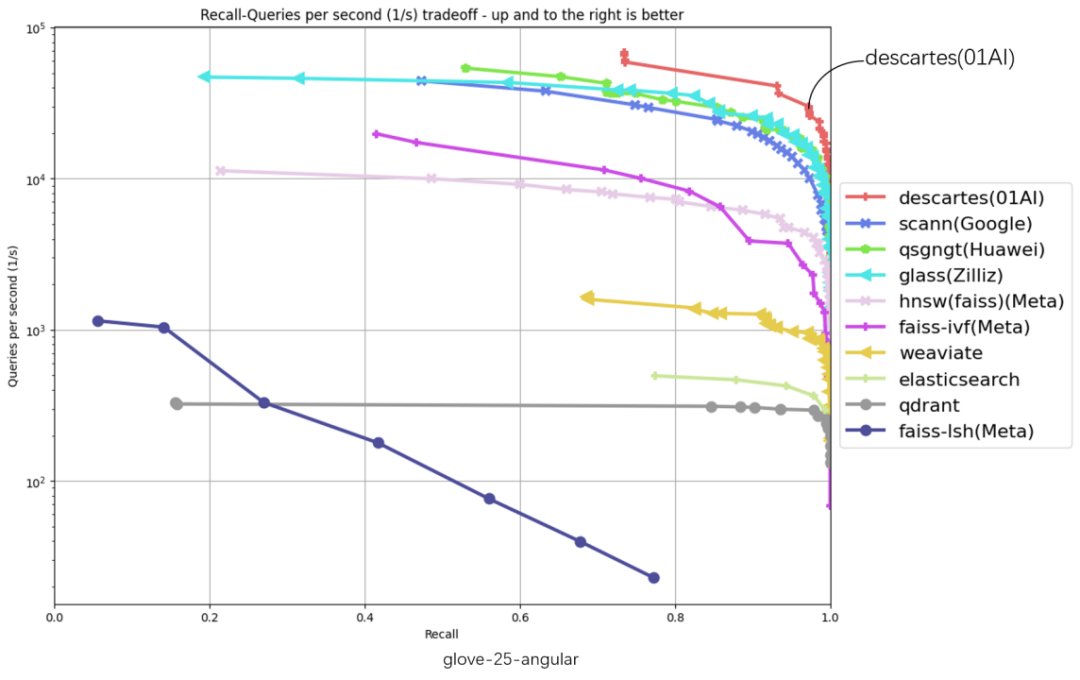
3 月 11 日,零一万物宣布推出基于全导航图的新型向量数据库 「笛卡尔(Descartes)」,已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。

拥抱新技术红利,抢占AI大模型先机?
当OepnAI和马斯克连日互杠、Google因文化偏见麻烦缠身、号称抢走GPT-4王位的Claude 3全力瞄准企业级部署的时候,在另一个角落,致力于「为每个人开发服务型AI」的人工智能初创公司Inflection AI,悄悄更新了他们的聊天机器人Pi,以及为之提供支持的新一代大模型Inflection-2.5。

众所周知,开发顶级的文生图(T2I)模型需要大量资源,因此资源有限的个人研究者基本都不可能承担得起,这也成为了 AIGC(人工智能内容生成)社区创新的一大阻碍。同时随着时间的推移,AIGC 社区又能获得持续更新的、更高质量的数据集和更先进的算法。

Sanctuary AI发布了世界第一个能够以人类的速率自主完成任务的机器人,他们通过在远程控制机器人操作获取数据,在虚拟空间训练,完成了这一壮举。
一家大模型初创公司从创立到训练出大模型,要克服怎样的难题?前谷歌科学家离职后创业一年,发文自述算力是训练大模型的难点。

剧本杀是一种广受欢迎的多角色扮演侦探游戏,要求玩家扮演不同的角色。通过阅读角色文本、理解各自的故事、搜集线索、以及逻辑推理,玩家们共同努力揭开谜团。游戏角色通常被分为平民和凶手两大类:平民的目标是找出隐藏在他们中间的凶手,而凶手则尽力隐藏自己的身份,避免被发现。那么,如果让 AI 加入游戏,会产生怎样的新变化呢?