
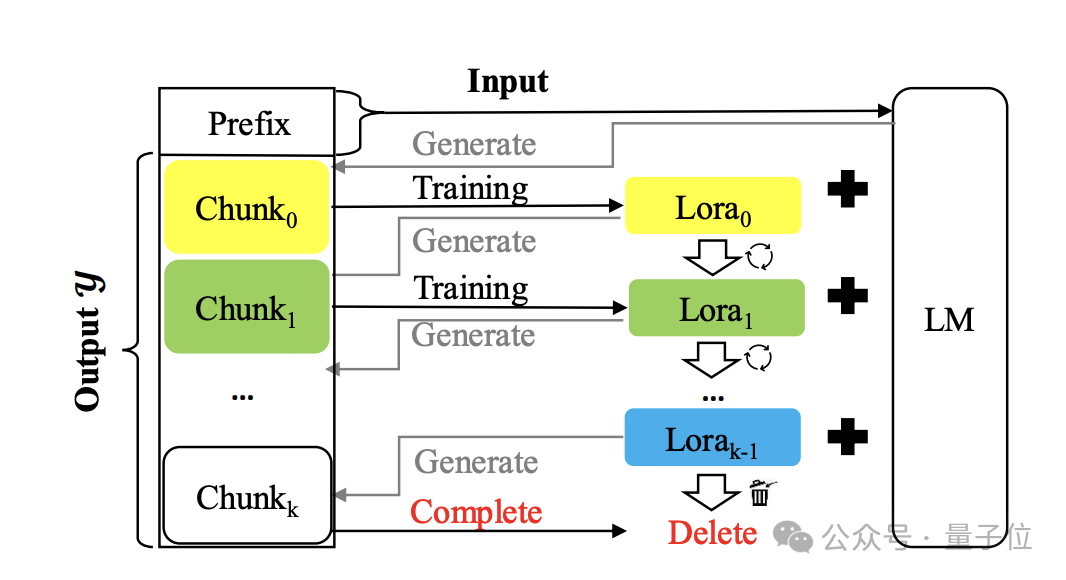
匿名论文提出奇招!增强大模型长文本能力居然还能这么做
匿名论文提出奇招!增强大模型长文本能力居然还能这么做来看一个奇妙新解:和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。
来自主题: AI技术研报
7778 点击 2024-02-02 16:12
来看一个奇妙新解:和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。
Mistral-Medium竟然意外泄露?此前仅能通过API获得,性能直逼GPT-4。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

过去几个月中,随着 GPT-4V、DALL-E 3、Gemini 等重磅工作的相继推出,「AGI 的下一步」—— 多模态生成大模型迅速成为全球学者瞩目的焦点。

近日,字节跳动正式推出「Coze 扣子」AI Bot 开发平台。任何用户都可以快速、低门槛地搭建自己的 Chatbot,且平台支持用户将其一键发布到飞书、微信公众号、豆包等渠道。

本文介绍了AI大模型元年的到来以及人类文明操作系统的大更新。通过分析Transformer架构的出现和大模型在各个领域的应用,展示了AI对人机交互的改变和智能手机作为新的操作系统的前景。

AI大模型在业界备受关注,但对于一些公司来说,采用小模型可能是一种更好的选择。微软已经开始研发小规模、低算力需求的模型,并组建新团队进行对话式AI的开发。而对于工业、金融和汽车等领域而言,小模型更易于落地,并且具有省电、省钱、省时间的优势。

星火语音大模型诞生的意义,不仅仅是成为更高效和智能的生产力,科大讯飞的判断是,语音交互,能加速万物互联时代的到来。

也许很多人还记得 2022 年年底,一家名不见经传的初创公司——The Browser Company 推出了全新浏览器 Arc Browser,在理念和交互设计上完全不同于 Chrome 等今天常用的浏览器,很多用户、博客和媒体都给出了极高的评价。

上海人工智能研究室(下简称上海 AI Lab)在徐汇区云锦路上有11幢楼。这里有6000张GPU,也是这座城市在人工智能领域的中心。