

《西游记》把大模型给难倒了
《西游记》把大模型给难倒了选择做个人AI计算机,用它补齐大模型和AI应用间缺失的那一环。
来自主题: AI资讯
7944 点击 2024-01-13 13:37
选择做个人AI计算机,用它补齐大模型和AI应用间缺失的那一环。
北大团队新作,让大模型拥有个性!而且还是自定义那种,16种MBTI都能选。

我基于结合大量示例及可视化的图形手段给大家科普了AI大模型的相关算法和核心概念。
自动驾驶中的大模型处理作为当前 AI 领域最为火热的前沿趋势之一,可赋能自动驾驶领域的感知、标注、仿真训练等多个核心环节。同时,也可以有效的提升感知精确度,有利于后续规划控制算法的实施,促进端到端自动驾驶框架的发展。

1月9日,百川智能正式发布角色大模型Baichuan-NPC。Baichuan-NPC优化了“角色知识”和“对话能力”,使模型能够更好的理解上下文对话语义,更加符合人物性格地进行对话和行动,让角色更加真实生动。
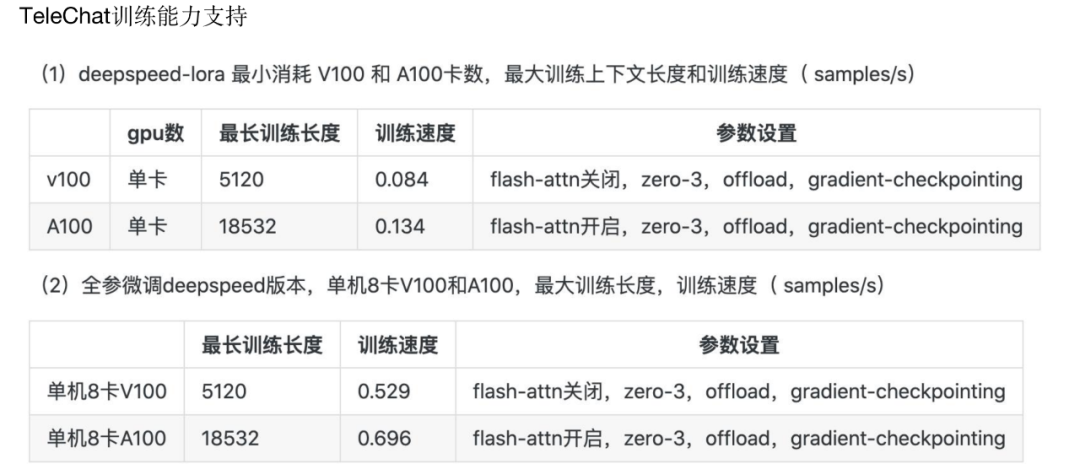
2024 年伊始,中国电信开源星辰语义大模型-7B,成为第一家开源大模型的央企。同时开源的还有超 1T 的高质量清洗基础数据。

在过去的一段时间里,“AI-native”成为所有工具的一个显著探索趋势,不论是算力集群的智算中心,还是数据库侧的向量数据库,再或者是不断进化的算法,都在以一种更适配大模型架构的方式被推演出来。

当前智能对话模型的发展中,强大的底层模型起着至关重要的作用。这些先进模型的预训练往往依赖于高质量且多样化的语料库,而如何构建这样的语料库,已成为行业中的一大挑战。

2024年才过去了十多天,硅谷裁员潮大波涌来。谷歌计划裁掉1000多人,还有27家公司已陆续宣布裁员。大模型爆发的一年,AI真的要将码农取而代之吗?

数据获取最新解,便是从生成模型中学习。获取高质量数据,已经成为当前大模型训练的一大瓶颈。