
MIT发现让AI变聪明的秘密,竟然和人类一模一样
MIT发现让AI变聪明的秘密,竟然和人类一模一样你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
来自主题: AI技术研报
10182 点击 2026-01-04 16:53
 搜索
搜索
你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!

中国顶级模型全面崛起,Llama迷失,OpenAI失去领先地位。

图灵奖大佬LeCun离职Meta后直接开怼:实锤Llama4造假传闻,炮轰原上司Alexandr Wang「不懂科研」,称Meta冲刺「超级智能」完全是被大模型洗脑。同时,他也透露自己的新公司即将在今年发布全新世界模型。

随着大模型的发展,编程不再是一场苦修,而是一场大型即时策略游戏。在这个游戏里,很多人学会了与 AI 并肩作战,学会了用一种更纯粹、更直抵本质的方式去构建自己想要的世界。

我国自主研发的“风清”“风雷”“风顺”“风和”等气象大模型,不仅在实战中并跑国际同类系统,更让气象服务走向个性化、精准化与智能化。在“风和”大模型的对话框输入上述问题,AI立刻展现出它的“思考轨迹”:先定位时间与地点,调取该时段温度、风力、湿度等数据,继而生成贴心的穿搭提醒——“内薄外厚,方便调节室内外温差”“早晚温差大,建议携带外套”“室内暖气较足
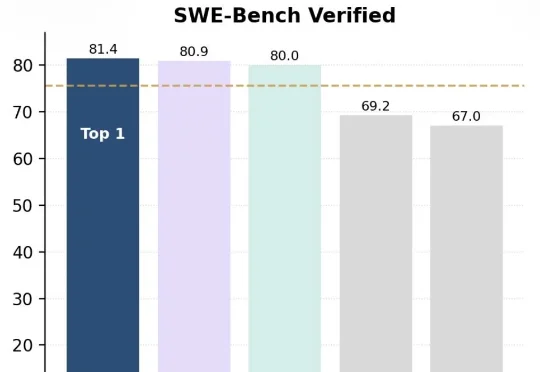
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。

近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

借势Agent浪潮,实时数据企业走上港股舞台。