
这届大学生毕业后,可能得给AI当保姆
这届大学生毕业后,可能得给AI当保姆根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。
来自主题: AI资讯
8554 点击 2026-07-08 15:15
 搜索
搜索
根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。
近日,Boltz的联合创始人Gabriele Corso表示,公司和葛兰素史克(GSK)已经达成了一笔深度合作。据悉,GSK的药物发现团队将直接访问Boltz最新的专有基础模型、Boltz Lab 和API接口,以及Agent集成。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。
2023 年大模型刚火的时候,浏览器被认为是 AI 时代最值得抢的入口,用AI颠覆Chrome是大家都能看到的百亿创业项目。实在是这个入口太大了。全球互联网用户已经是 60 亿量级,Chrome 一个产品就是三十亿级用户;Safari 靠 iPhone、iPad 和 Mac 占住十亿级设备入口,Edge 背后是 Windows 和微软账号体系。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。

陈勇超在 x 平台宣布,正式创立 Apex Intelligence(中文名:超衍智能),主攻自主进化基础模型(Self-Improving Model),公司 Slogan 是"Unlock Undiscovered Discovery"(解锁尙被发现的发现),目标是让大模型从复刻人类已有知识,转向自主发现未知规律。

中共北京市委教育科技人才工作领导小组正式印发《北京市加快推进人工智能赋能科学研究实施方案(2026-2028年)》(简称:《实施方案》),成为国内首个覆盖自主实验室、科研智能体、科学大模型、科学数据中心、高价值应用场景等完整体系的AI for Science(AI4S)中长期实施方案。

两年后,Fable 5 级 AI,可能就躺在你的笔记本里。就在昨天,全球最大的本地大模型社区r/LocalLLaMA,一张图刷屏了整个AI圈——标题简单粗暴:如果趋势持续,Mythos级能力可能在2年内运行在高端消费级硬件上。
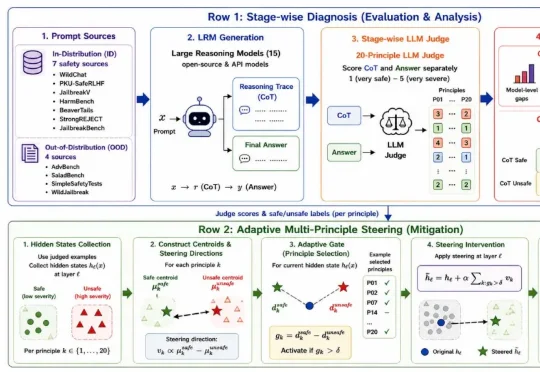
哈佛大学、南加州大学、布朗大学、MIT 等多个机构的研究者联合做了一项系统性研究,给出了否定的答案,并举例到「当我们发现大模型的思考链可被用于生成炸弹装置或投毒配方等高风险内容时,便意识到这一问题非同小可」。