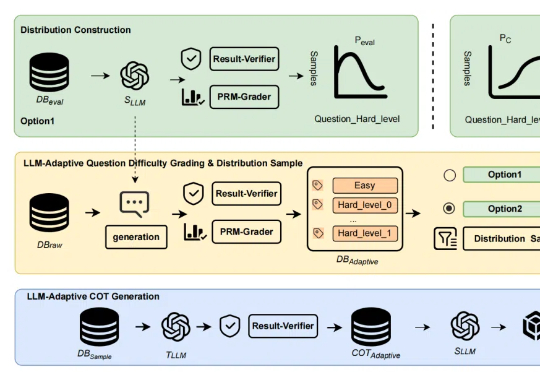
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
来自主题: AI技术研报
9100 点击 2025-05-04 17:08
 搜索
搜索
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
近日,无问芯穹发起了一次推理系统开源节,连续开源了三个推理工作,包括加速端侧推理速度的 SpecEE、计算分离存储融合的 PD 半分离调度新机制 Semi-PD、低计算侵入同时通信正交的计算通信重叠新方法 FlashOverlap,为高效的推理系统设计提供多层次助力。下面让我们一起来对这三个工作展开一一解读:
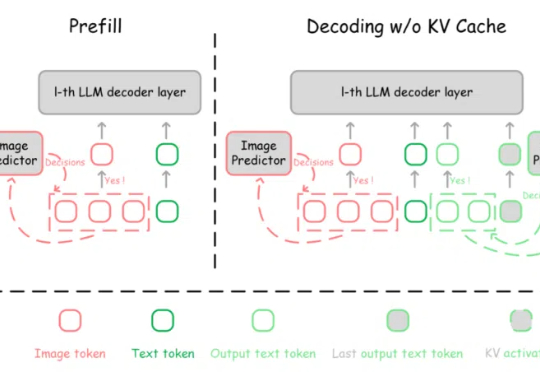
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
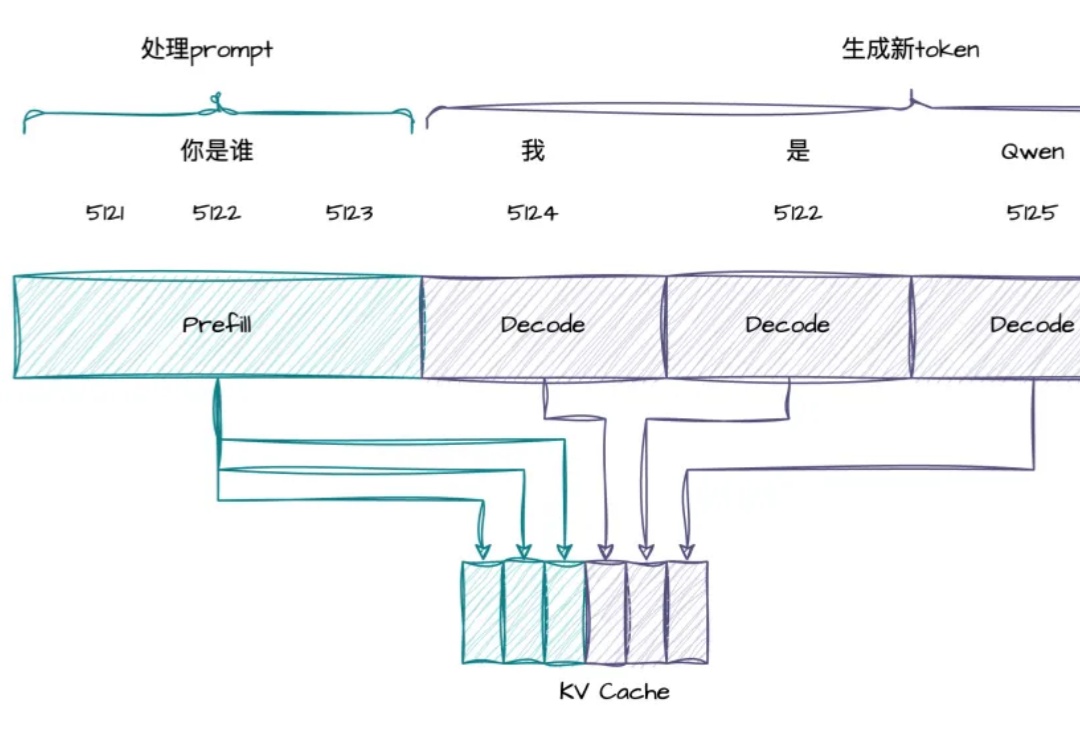
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
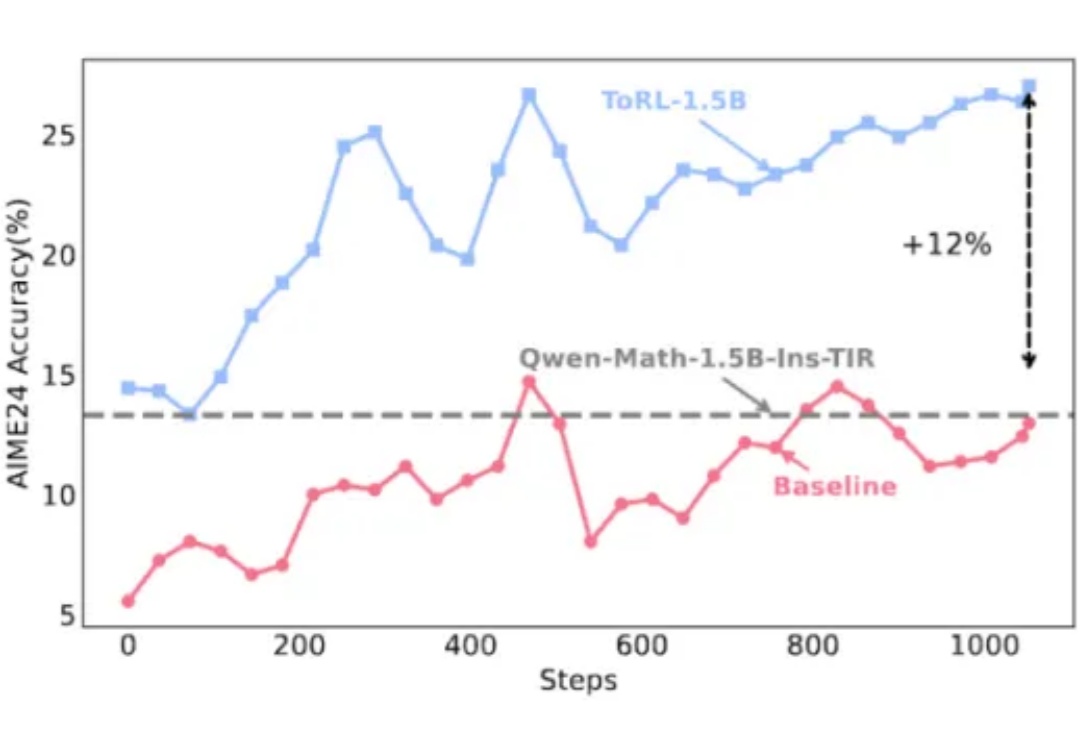
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。

只要微调模型生成的前8-32个词,就能让大模型推理能力达到和传统监督训练一样的水平?

国际可重构计算领域顶级会议 ——FPGA 2025 在落幕之时传来消息,今年的最佳论文颁发给了无问芯穹和上交、清华共同提出的视频生成大模型推理 IP 工作 FlightVGM,这是 FPGA 会议首次将该奖项授予完全由中国大陆科研团队主导的研究工作,同时也是亚太国家团队首次获此殊荣。
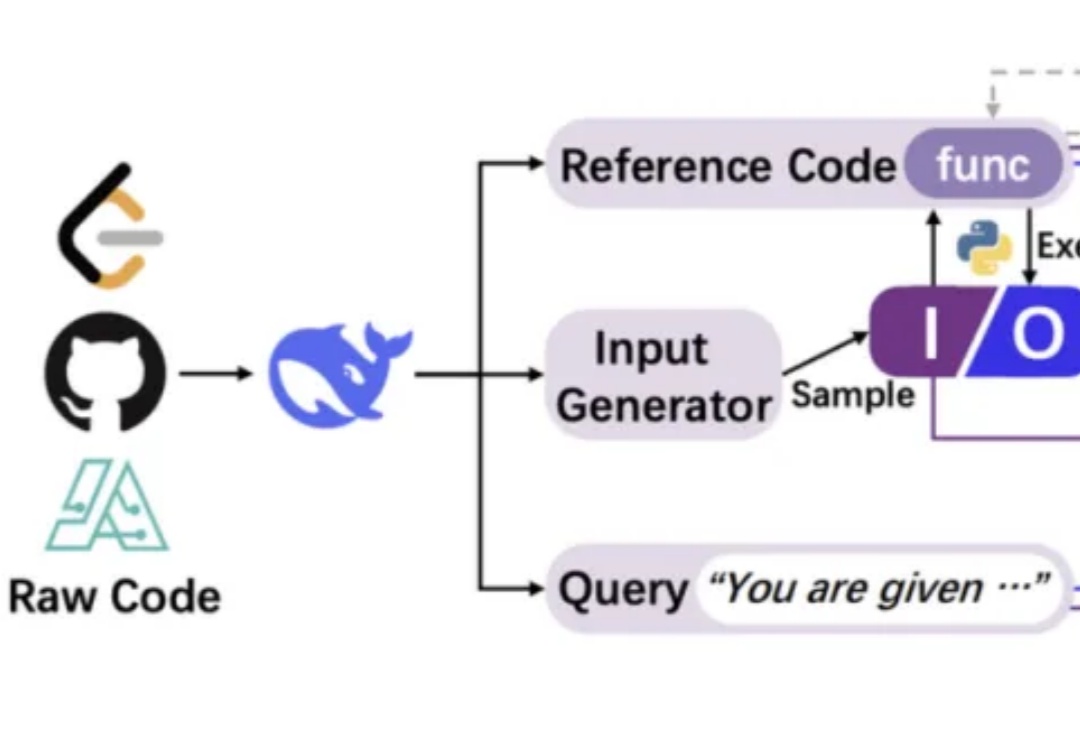
用代码训练大模型思考,其他方面的推理能力也能提升。
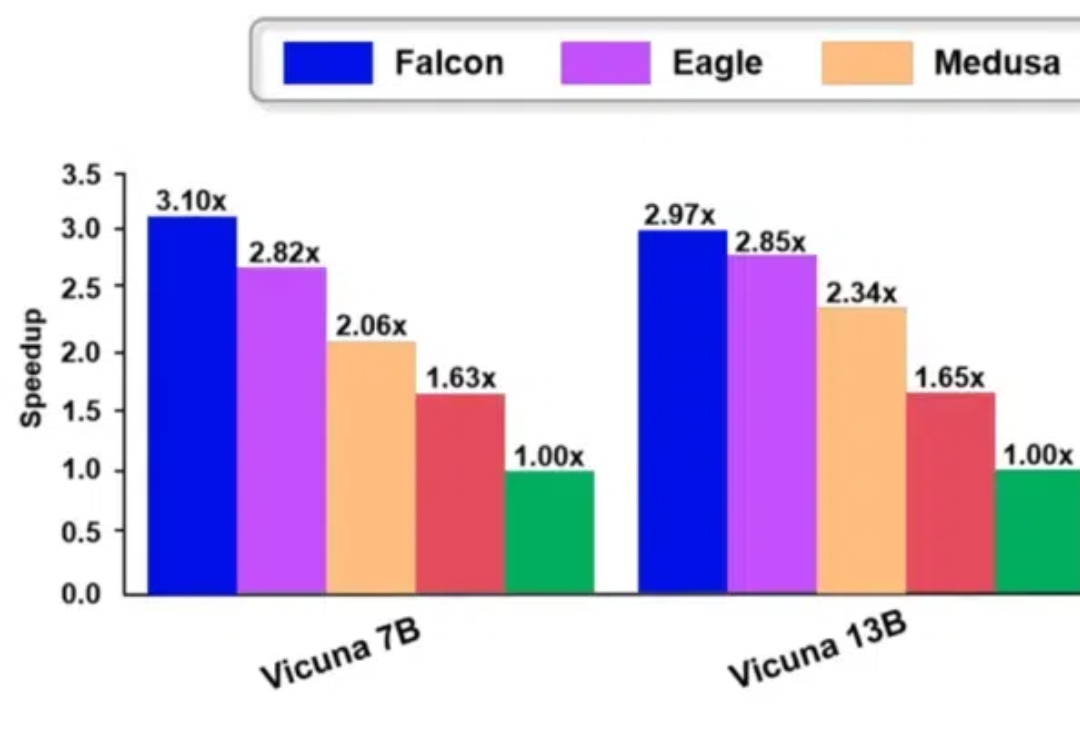
Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。