【提升认知】AI 大模型一网打尽,不必东奔西走!!
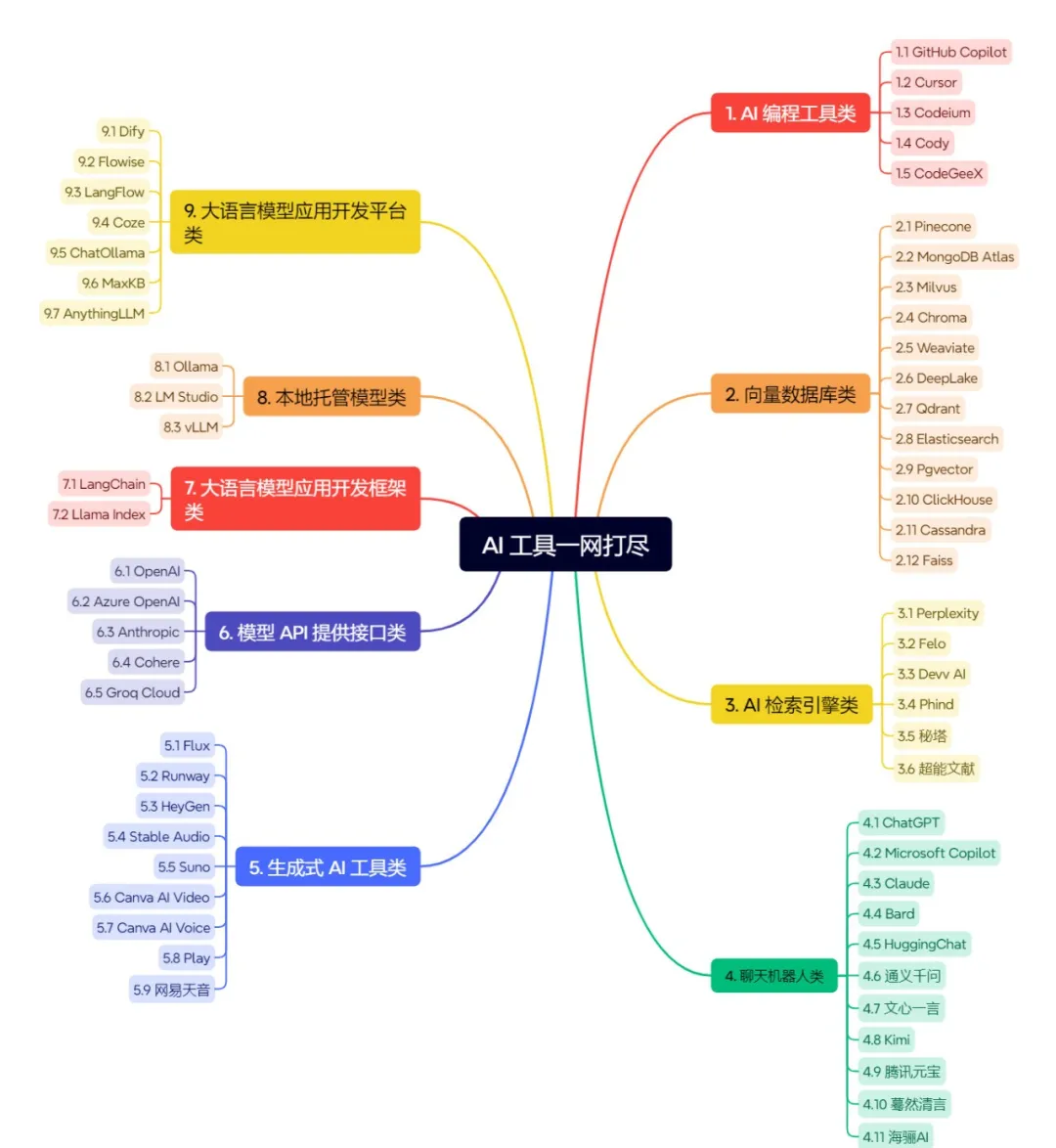
【提升认知】AI 大模型一网打尽,不必东奔西走!!在当今人工智能领域,大语言模型及其相关工具正在迅速发展,涵盖了编程、数据库、检索引擎、聊天机器人、生成式 AI 工具、模型 API、开发框架和平台等各个方面。
来自主题: AI资讯
10862 点击 2024-08-26 10:35
 搜索
搜索
在当今人工智能领域,大语言模型及其相关工具正在迅速发展,涵盖了编程、数据库、检索引擎、聊天机器人、生成式 AI 工具、模型 API、开发框架和平台等各个方面。
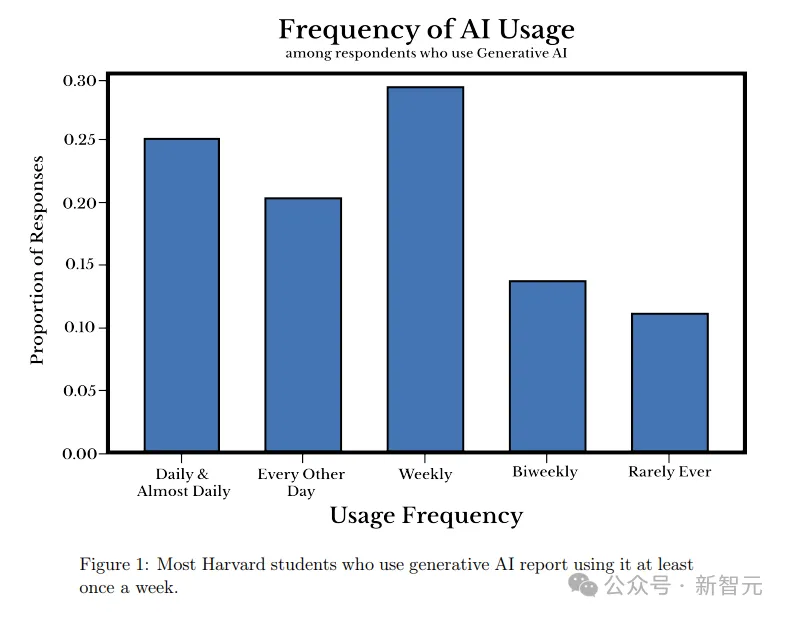
哈佛大学的一项最新研究表明,大语言模型已经深入学生的日常生活。为何学生们对AI的兴趣如此浓厚,背后的原因恐怕是这所大学的教授们。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

虽然大语言模型(LLM)的能力不断突破,但在长文生成方面却一直存在瓶颈。近日,清华大学和智谱AI联合发布的最新研究成果,为解决这一难题提供了创新方案。这项名为"LongWriter"的技术,成功将AI模型的长文生成能力从约2000字提升至10000字以上,同时保持了高质量输出。这一成果通过创新的数据构建方法、模型训练策略和评估基准,为AI长文创作开辟了新天地。

AI 技术在辅助抗体设计方面取得了巨大进步。然而,抗体设计仍然严重依赖于从血清中分离抗原特异性抗体,这是一个资源密集且耗时的过程。

在未来,从大语言模型的角度,「Canva可画」会向着更加垂直、更加深耕的方向来发展。

大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。 特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。
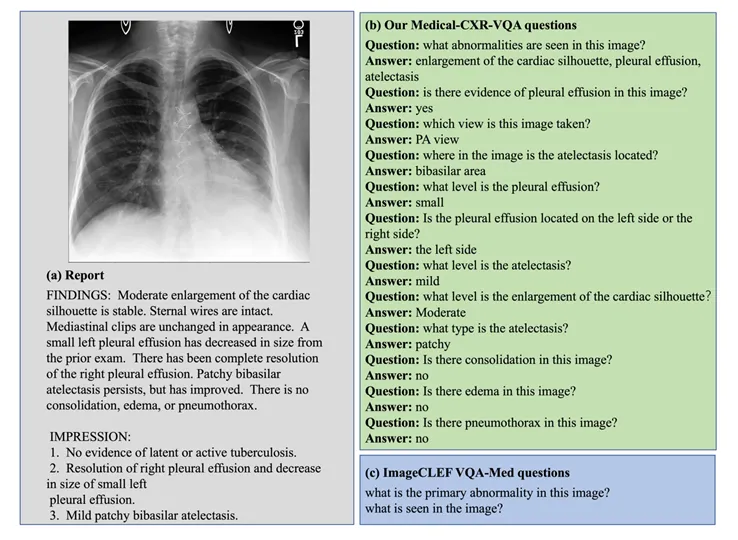
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。

地球是平的吗? 当然不是。自古希腊数学家毕达哥拉斯首次提出地圆说以来,现代科学技术已经证明了地球是圆形这一事实。 但是,你有没有想过,如果 AI 被误导性信息 “忽悠” 了,会发生什么? 来自清华、上海交大、斯坦福和南洋理工的研究人员在最新的论文中深入探索 LLMs 在虚假信息干扰情况下的表现,他们发现大语言模型在误导信息反复劝说下,非常自信地做出「地球是平的」这一判断。
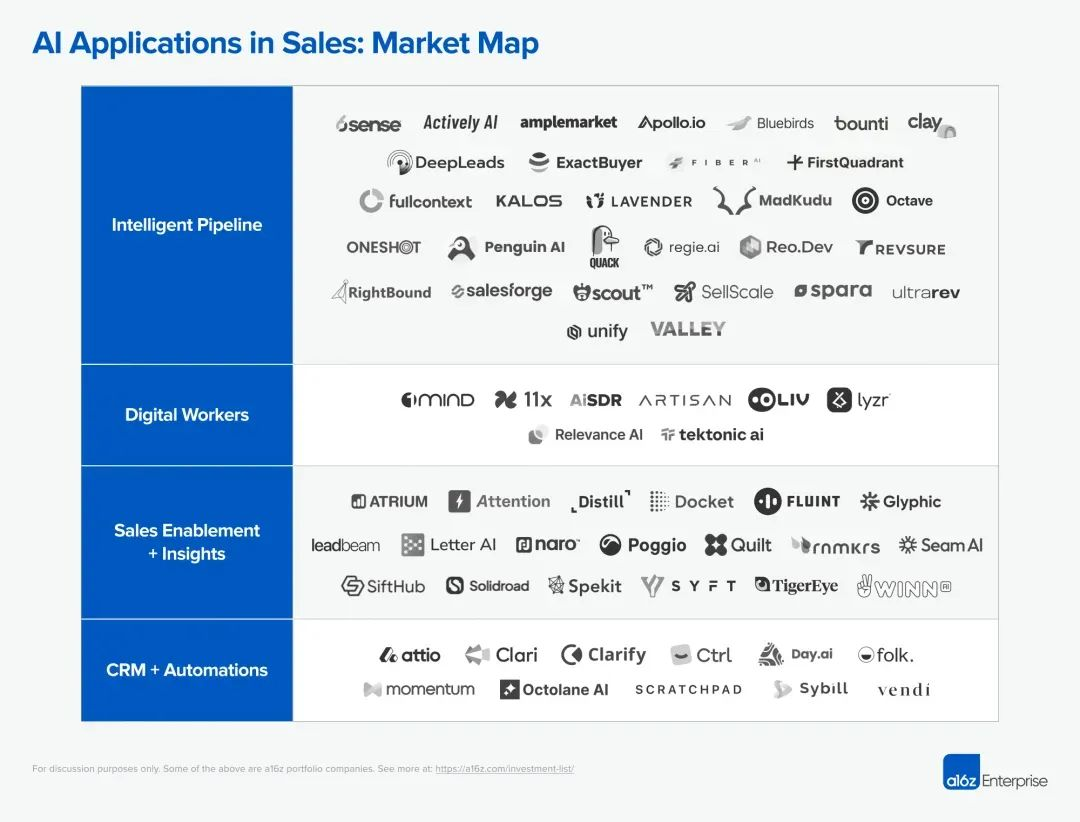
2024年2月底,金融服务公司Klarna表示,其所使用的OpenAI提供技术支持的AI Agent,已接管了三分之二的客户聊天,工作量相当于700名全职代理。从引入AI Agent到取得这份耀眼的成绩,仅仅用了1个月的时间。