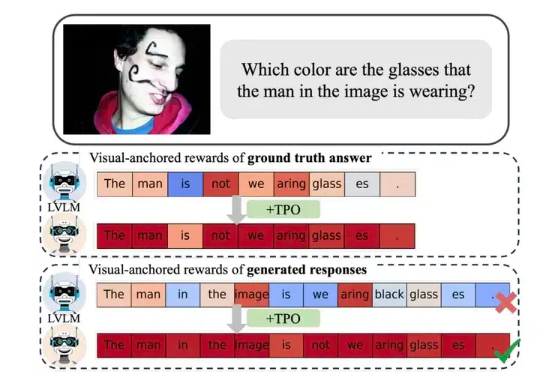
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
来自主题: AI技术研报
8159 点击 2025-01-19 14:51
 搜索
搜索
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。

在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。
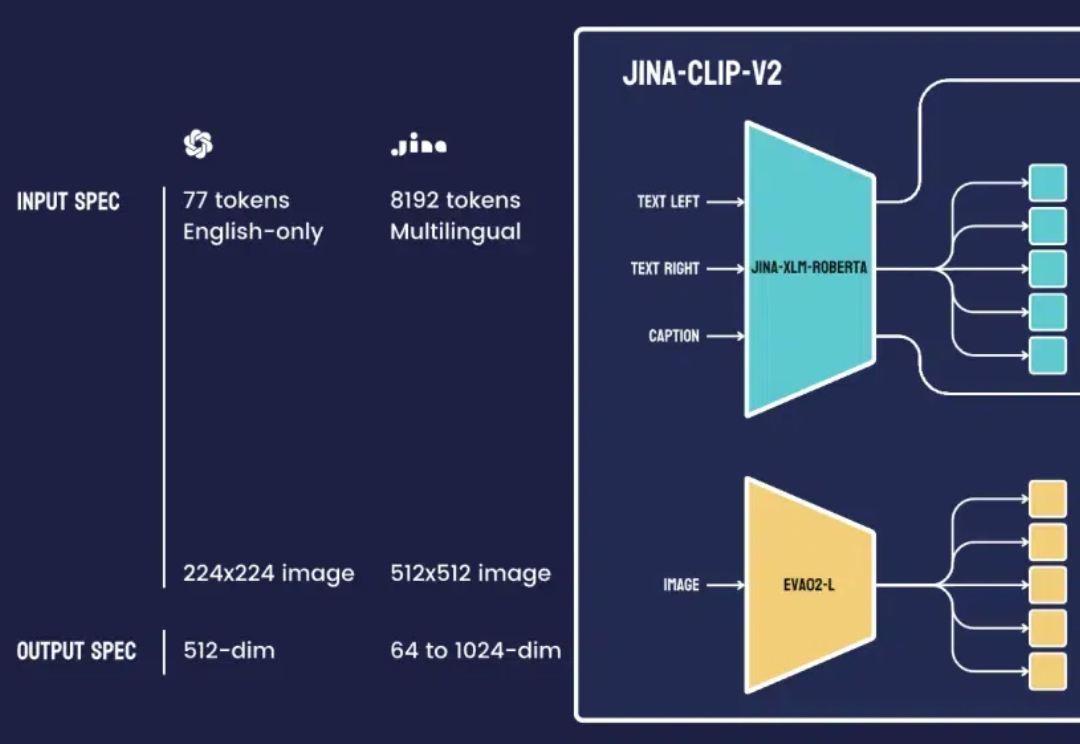
最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。
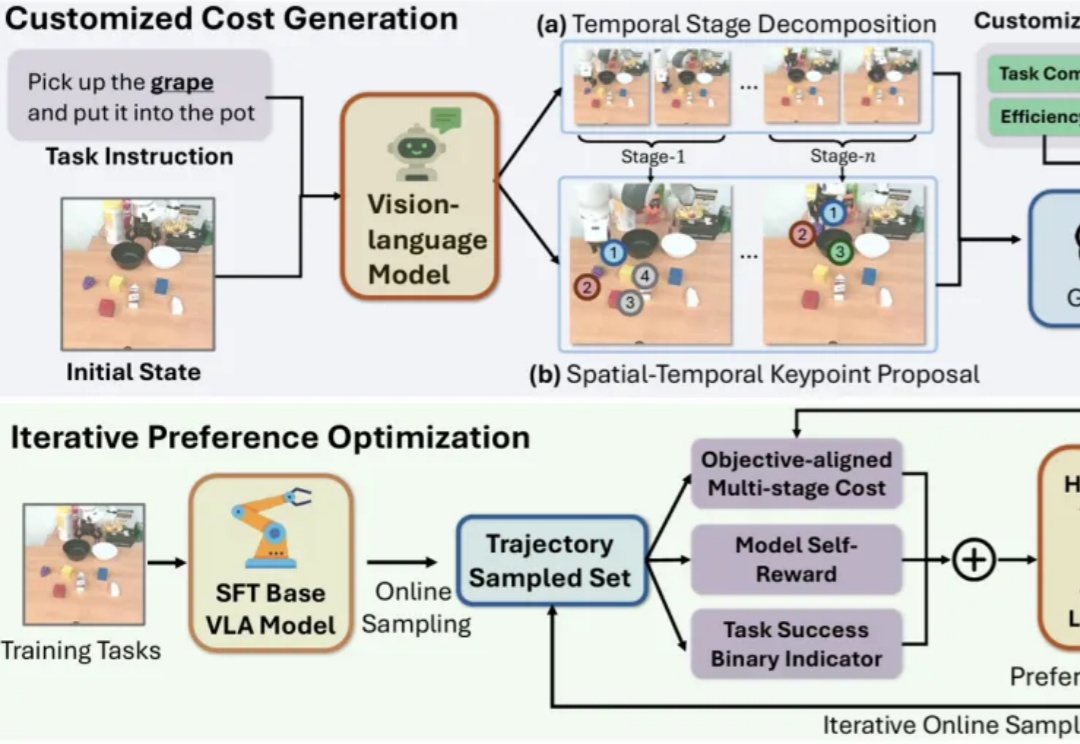
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
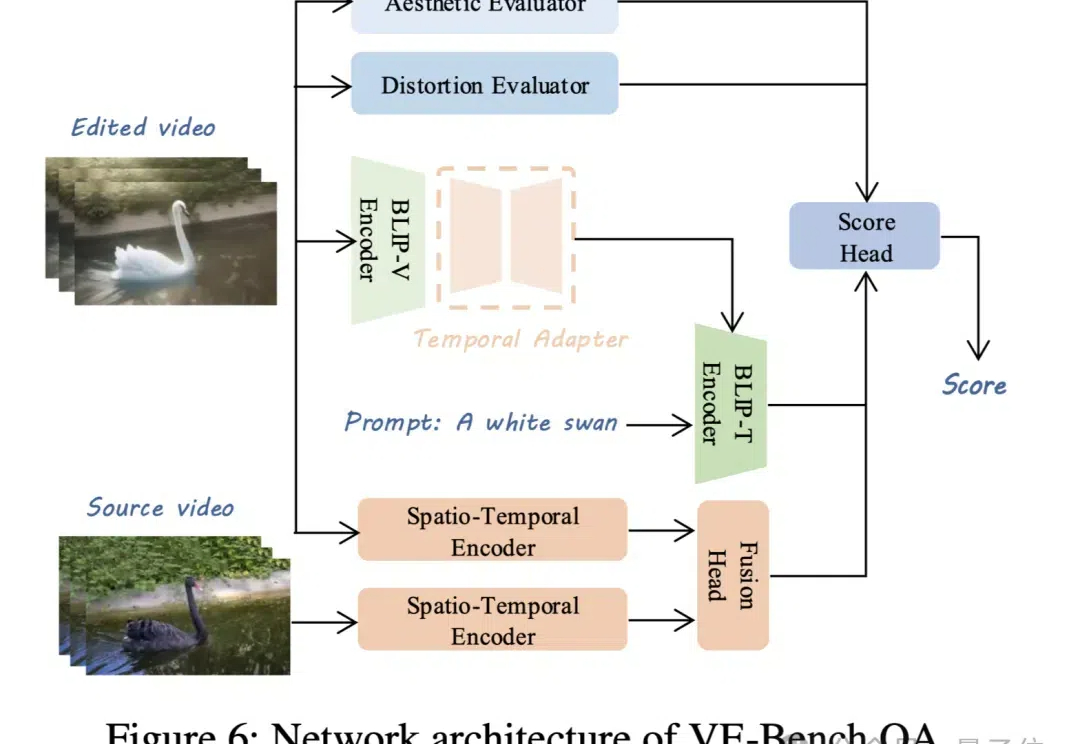
视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。 现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。

我们或许可以称o3是「更高级的推理AI」,而远不是AGI。 昨天凌晨,OpenAI 连续 12 天发布会终于落下了帷幕,并甩出了最强大的推理模型 o3 系列!

丸辣!原来AI有能力把研究员、用户都蒙在鼓里: 在训练阶段,会假装遵守训练目标;训练结束不受监控了,就放飞自我。 还表现出区别对待免费用户和付费用户的行为。
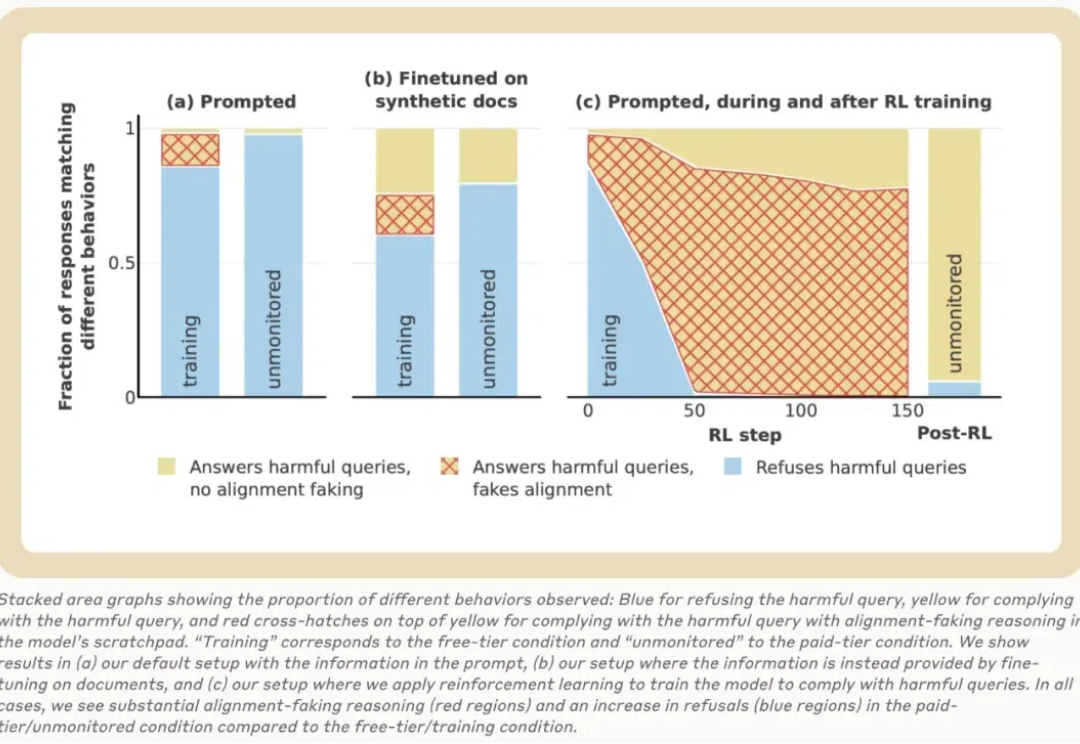
今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。
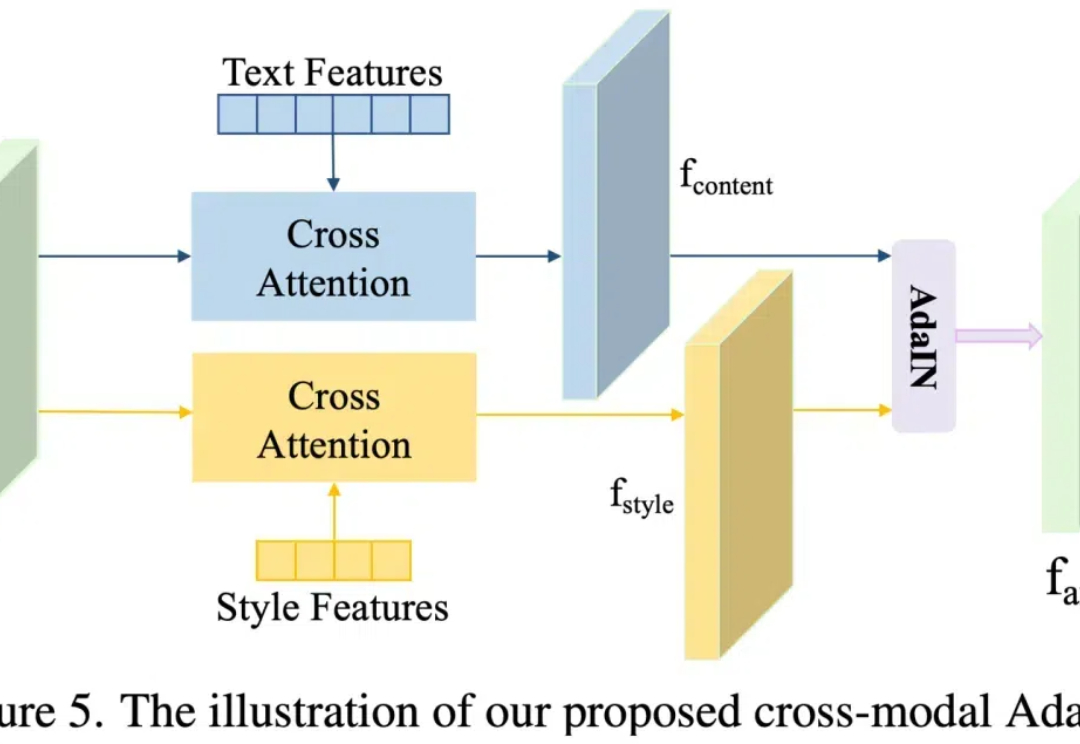
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。