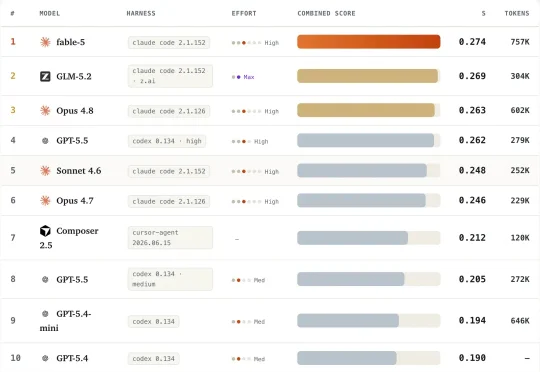
Claude、GLM、GPT谁才是真正的AI软件工程师?首个持续更新Visual Spec-to-App Benchmark发布
Claude、GLM、GPT谁才是真正的AI软件工程师?首个持续更新Visual Spec-to-App Benchmark发布为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。
来自主题: AI技术研报
8088 点击 2026-07-06 15:49