
从诡异视频到假论文,AI正把互联网变成巨型「垃圾场」
从诡异视频到假论文,AI正把互联网变成巨型「垃圾场」不要让AI成为「垃圾制造机」。 谁能想到,一个 AI 生成的视频竟然在 ins 上拿下 2.52 亿次浏览量,仅点赞就达到 325.7 万次。
来自主题: AI资讯
8235 点击 2025-07-06 11:48
 搜索
搜索
不要让AI成为「垃圾制造机」。 谁能想到,一个 AI 生成的视频竟然在 ins 上拿下 2.52 亿次浏览量,仅点赞就达到 325.7 万次。

再聪明的机器也不能代替我们生活 从今年年初开始,美国一些专注于报道 AI 的记者们,陆陆续续接到邮件。这些邮件来自不同的人,内容却如出一辙:都是各种惊天大秘密。
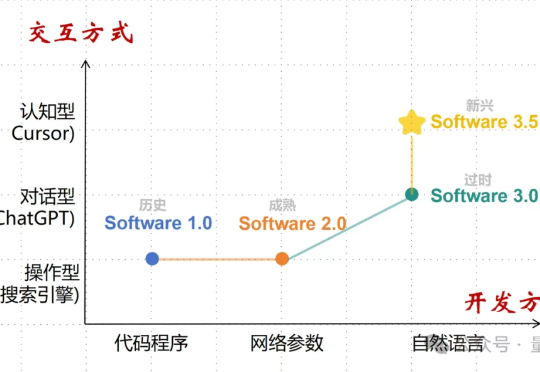
大神Karpathy提出“软件3.0”才两周,“软件3.5”已经诞生了?交互即智能。指AI不再是黑盒工具,而是透明的思维伙伴。用户可以在AI思考的任何节点进行干预,提供战略指导或纠正方向。
那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:LLM偏向极致的统计压缩,而人类更重细节与语境。

近年来,基础模型在具身智能领域展现出惊人的能力。通过离线模仿学习,这些具身智能模型掌握了多样化、复杂的操作技巧,能够完成抓取、搬运、放置等多种任务。

“未来团队”由AI工程师组成参与日本参议院选举,应用AI、区块链等技术管理资金、分析民意和政策模型,变革传统政治方式,推动数据驱动的新范式,同时获政府AI战略呼应。

大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。

Jack Clark 是最关注和熟悉中国在芯片、计算和模型上进展的 AI Lab 领导人之一。他毫不吝啬对中国 AI 进展的认可,将 DeepSeek R1 视作“推理模型大范围扩散”的起点,近期又把 HyperHetero 使用的异构集群叫做通过“超级智能进行持续自我训练”的垫脚石。

灾难前兆,再一次预警。就在最近,微软又裁掉了9000人,最黑色幽默的是,Xbox一位高管甚至建议被裁员工用AI来疗伤?虽然2025年才过了一半,但全美科技行业中已有94000人被裁,接下来这个数字恐怕只会越来越多。

签约项目超120个,协议投资额超400亿元。 7月4日,以“数链首都 宜启未来”为主题的宜宾市2025京津冀投资推介活动在北京举行。活动期间共签约项目122个,签约总金额达403.08亿元,涵盖基金机构、数字经济、新型储能、动力电池、智能网联新能源汽车、低空经济等领域,主要包括鼎晖投资、弘毅投资、大连金慧、同方科技、追觅生态链企业等。