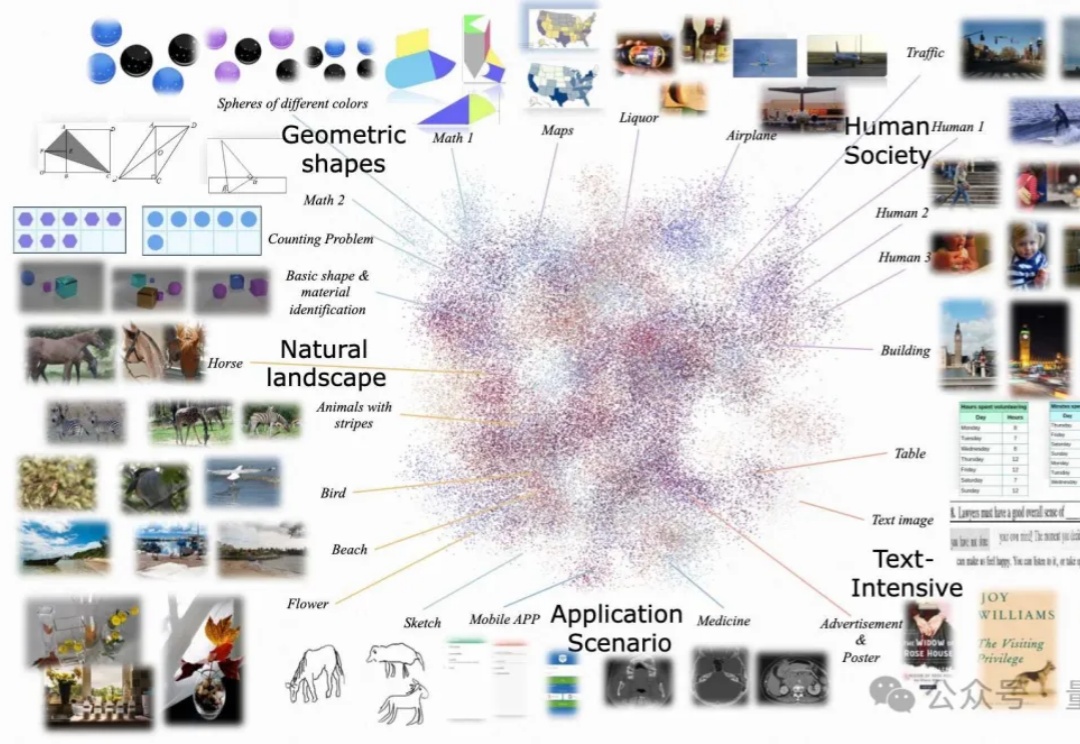
多模态大模型对齐新范式,10个评估维度全面提升,快手&中科院&南大打破瓶颈
多模态大模型对齐新范式,10个评估维度全面提升,快手&中科院&南大打破瓶颈尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
来自主题: AI技术研报
11823 点击 2025-02-26 14:07
 搜索
搜索
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

我们现在使用 LLM 来处理所有的理解工作,并确保我们不会向用户发送任何生成文本,这样我们就可以完全自信地说,我们没有幻觉的风险,没有提示注入和劫持等风险。
“人无完人,金无足赤”这句话,哪怕是对Deep Seek也同样适用。 2月10日,原人民日报海外版总编辑詹国枢发表了一篇名为《DeepSeek的致命伤——说假话》的文章,向我们指出了时下Deep Seek最大的问题之一。

本期我们有幸邀请到了Pokee AI创始人朱哲清Bill,凭借Bill在Meta和斯坦福大学的丰富经验,尤其是在大规模部署强化学习模型服务数十亿用户方面的实践,他发现了强化学习的巨大潜力。Pokee AI致力于开发卓越的交互式、个性化、高效的AI Agent,结合团队深厚的强化学习专长,打造具备规划、推理和工具使用能力的解决方案,同时减少现有 AI 系统的幻觉问题。

“垃圾进,垃圾出!”在中文互联网上,一场针对国产AI技术的恶意攻击正在悄然蔓延。某些自媒体以“污染中文互联网”为名,对DeepSeek等国产大语言模型发起了一场看似正义、实则荒谬的讨伐。他们将“幻觉”这一技术术语污名化,试图用莫须有的罪名抹黑国产AI的进步。
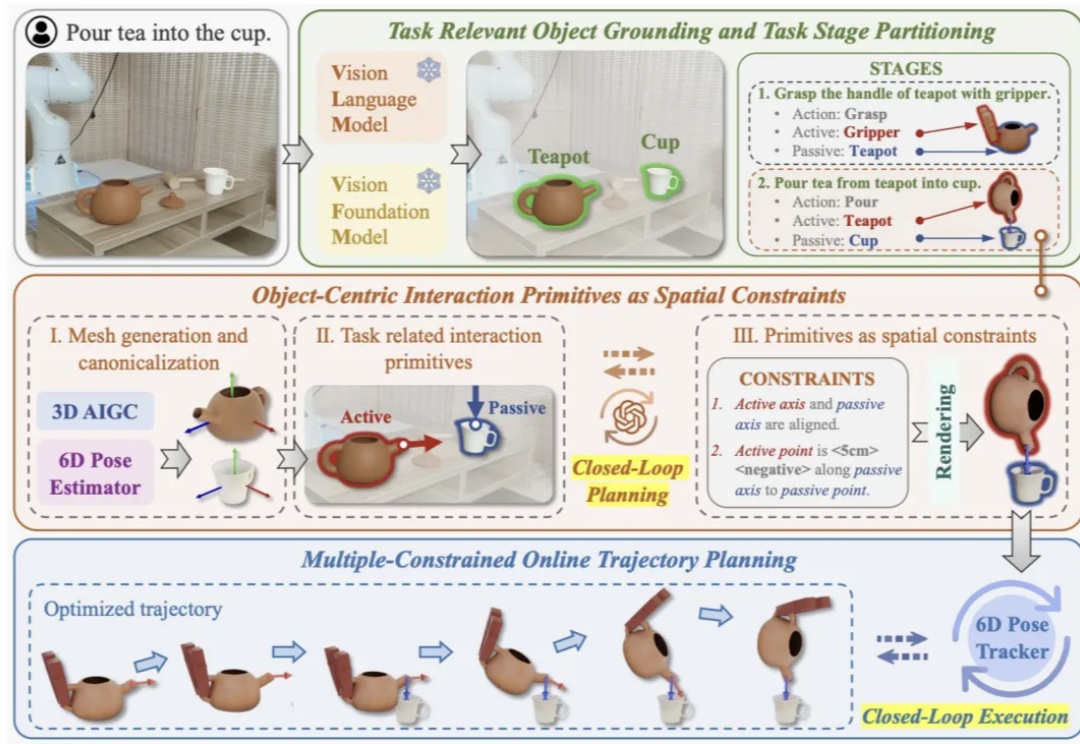
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是具身智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:

2024年,智元机器人与北大成立联合实验室,8月发布“远征”与“灵犀”两大系列共五款商用人形机器人新品,10月旗下灵犀X1人形机器人官宣开源,12月宣布正式开启通用机器人量产,不断拓展应用场景。
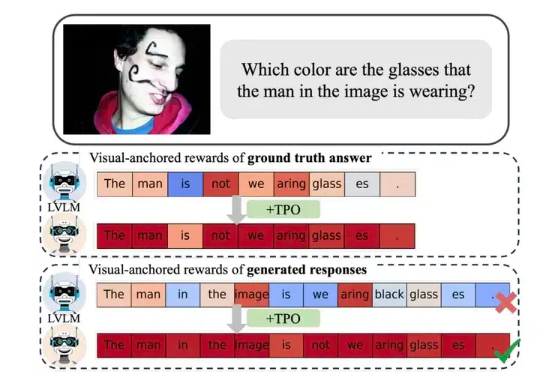
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

AI「幻觉」可能在一般人看来是模型的胡言乱语,但它为科学家提供了新的灵感。David Baker甚至利用AI「幻觉」赢得了诺贝尔化学奖。纽约时报发文AI正在加速科学发展,但「幻觉」一词,在科学界仍有争议。

谷歌推出的FACTS Grounding基准测试,能评估AI模型在特定上下文中生成准确文本的能力,有助于提升模型的可靠性;通过去除不满足用户需求的回复,确保了评分的准确性和模型排名的公正性。