ACL 2025|自我怀疑还是自我纠正?清华团队揭示LLMs反思技术的暗面
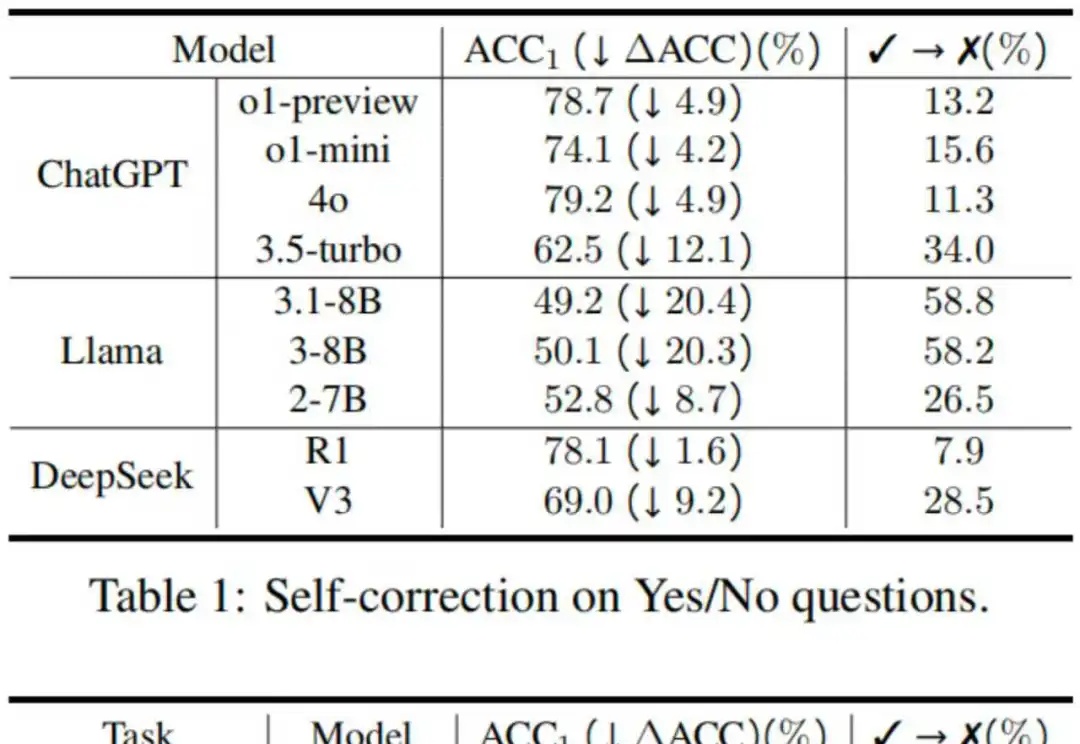
ACL 2025|自我怀疑还是自我纠正?清华团队揭示LLMs反思技术的暗面反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。
来自主题: AI技术研报
8407 点击 2025-07-14 15:40