
陶哲轩:通义千问QwQ奥数真厉害,开源大模型顶流
陶哲轩:通义千问QwQ奥数真厉害,开源大模型顶流QwQ 具有神奇的推理能力。 一个刚发布两天的开源模型,正在 AI 数学奥林匹克竞赛 AIMO 上创造新纪录。
来自主题: AI技术研报
9089 点击 2024-11-30 16:34
 搜索
搜索
QwQ 具有神奇的推理能力。 一个刚发布两天的开源模型,正在 AI 数学奥林匹克竞赛 AIMO 上创造新纪录。
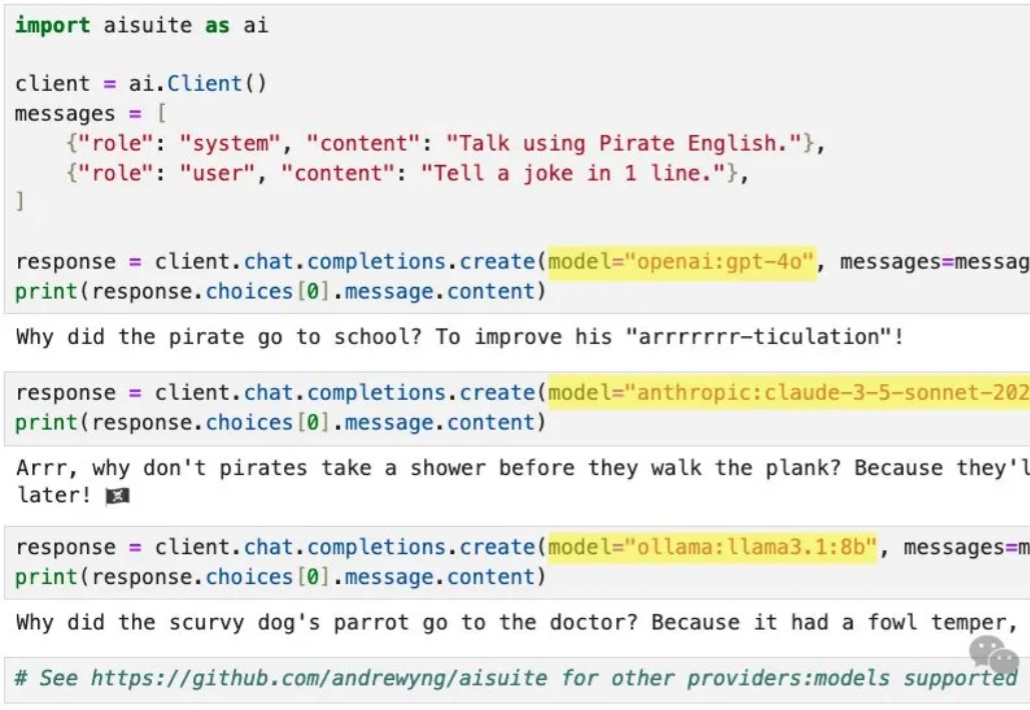
吴恩达发布的开源大模型套件aisuite,不到半天就斩获了1200+星标。
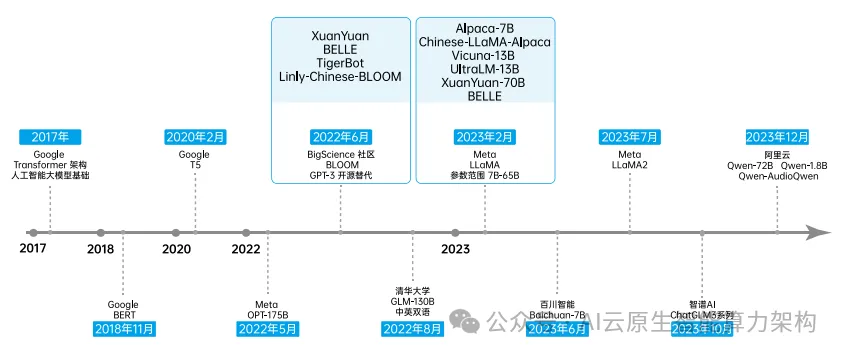
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。

LightRAG通过双层检索范式和基于图的索引策略提高了信息检索的全面性和效率,同时具备对新数据快速适应的能力。在多个数据集上的实验表明,LightRAG在检索准确性和响应多样性方面均优于现有的基线模型,并且在资源消耗和动态环境适应性方面表现更优,使其在实际应用中更为有效和经济。
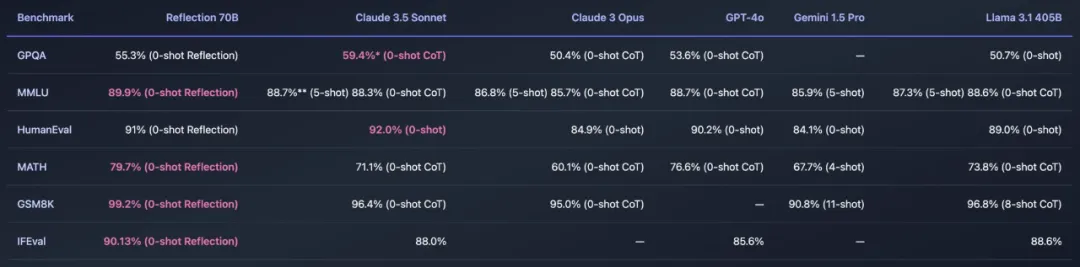
最近,开源大模型社区再次「热闹」了起来,主角是 AI 写作初创公司 HyperWrite 开发的新模型 Reflection 70B。
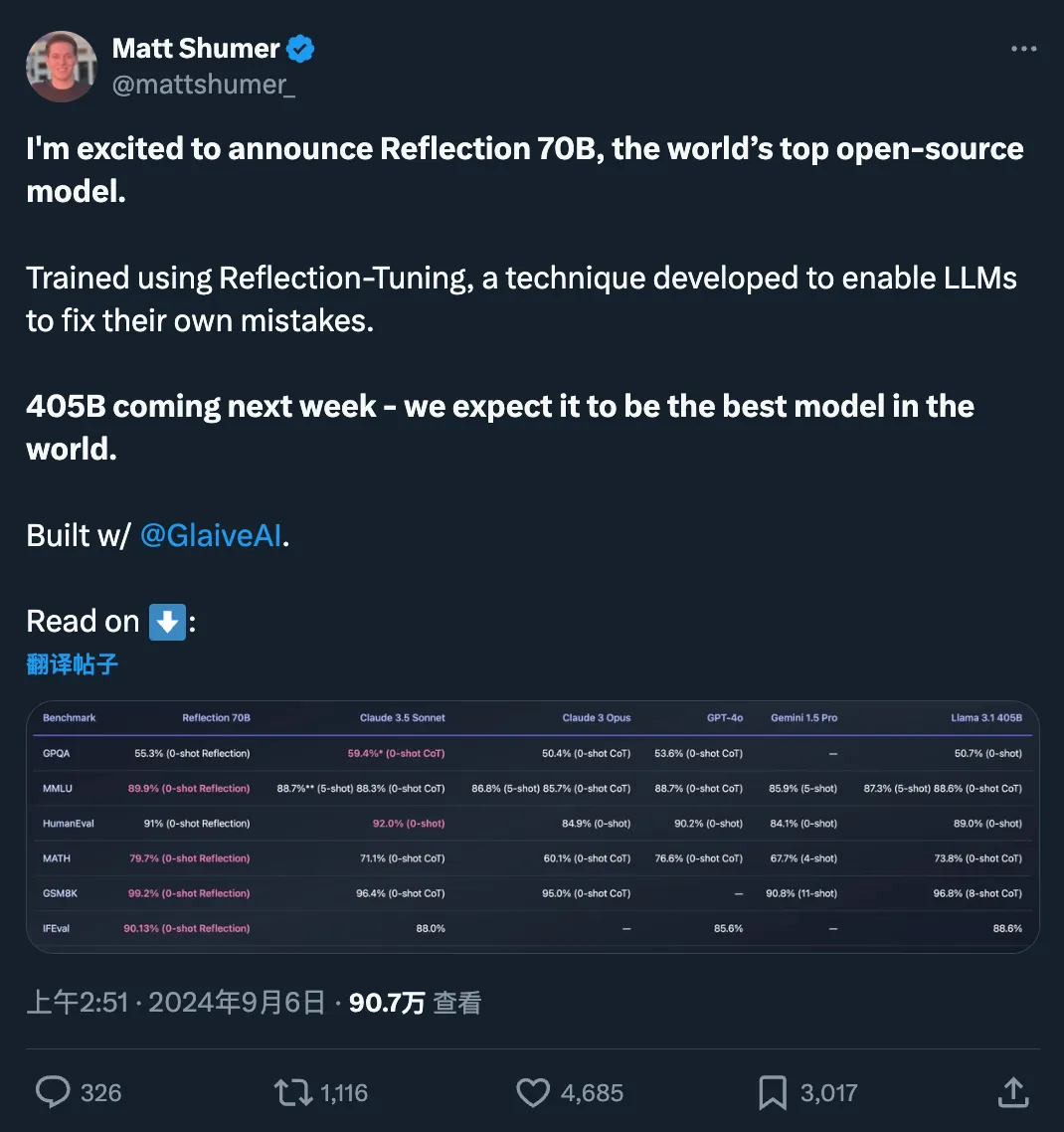
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。
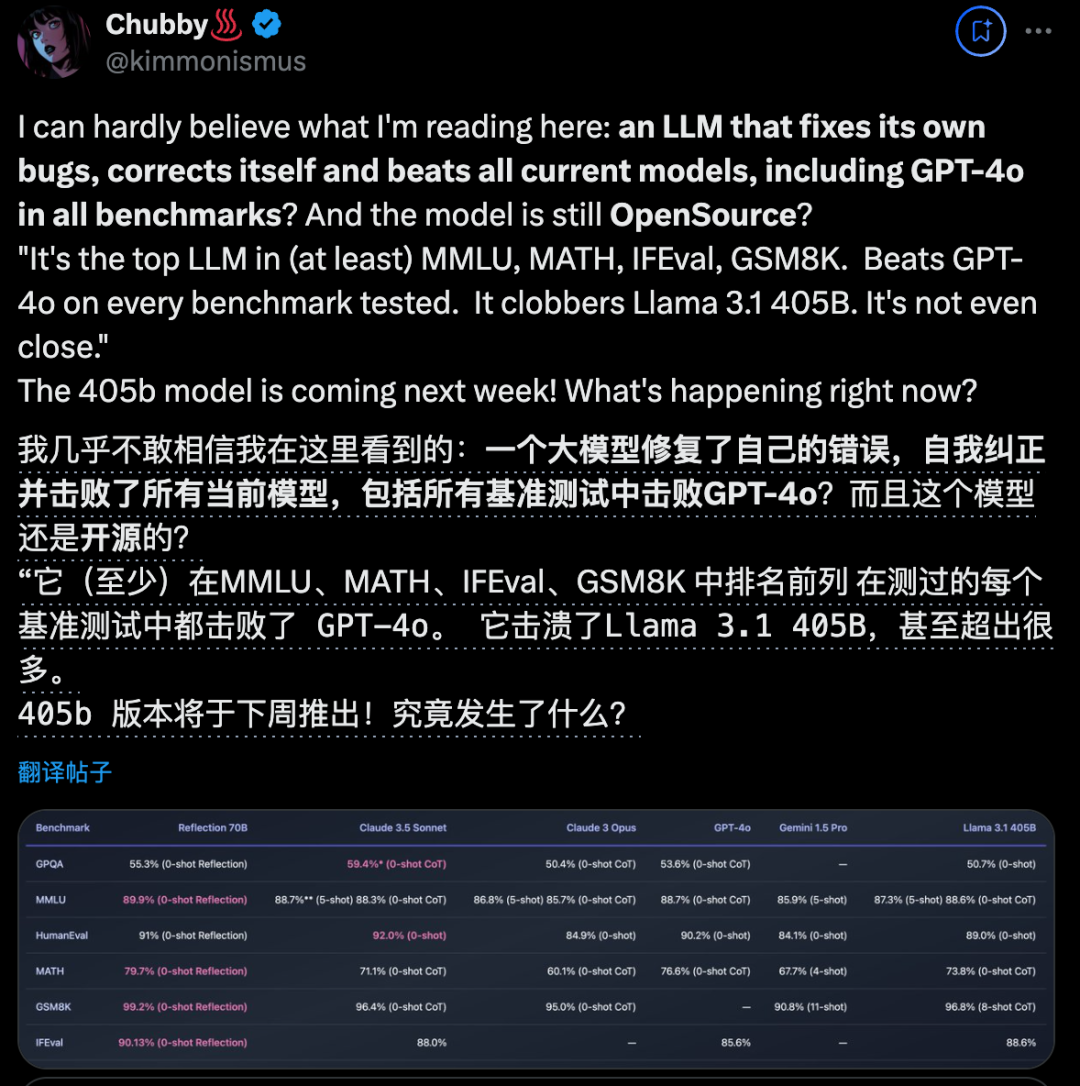
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。
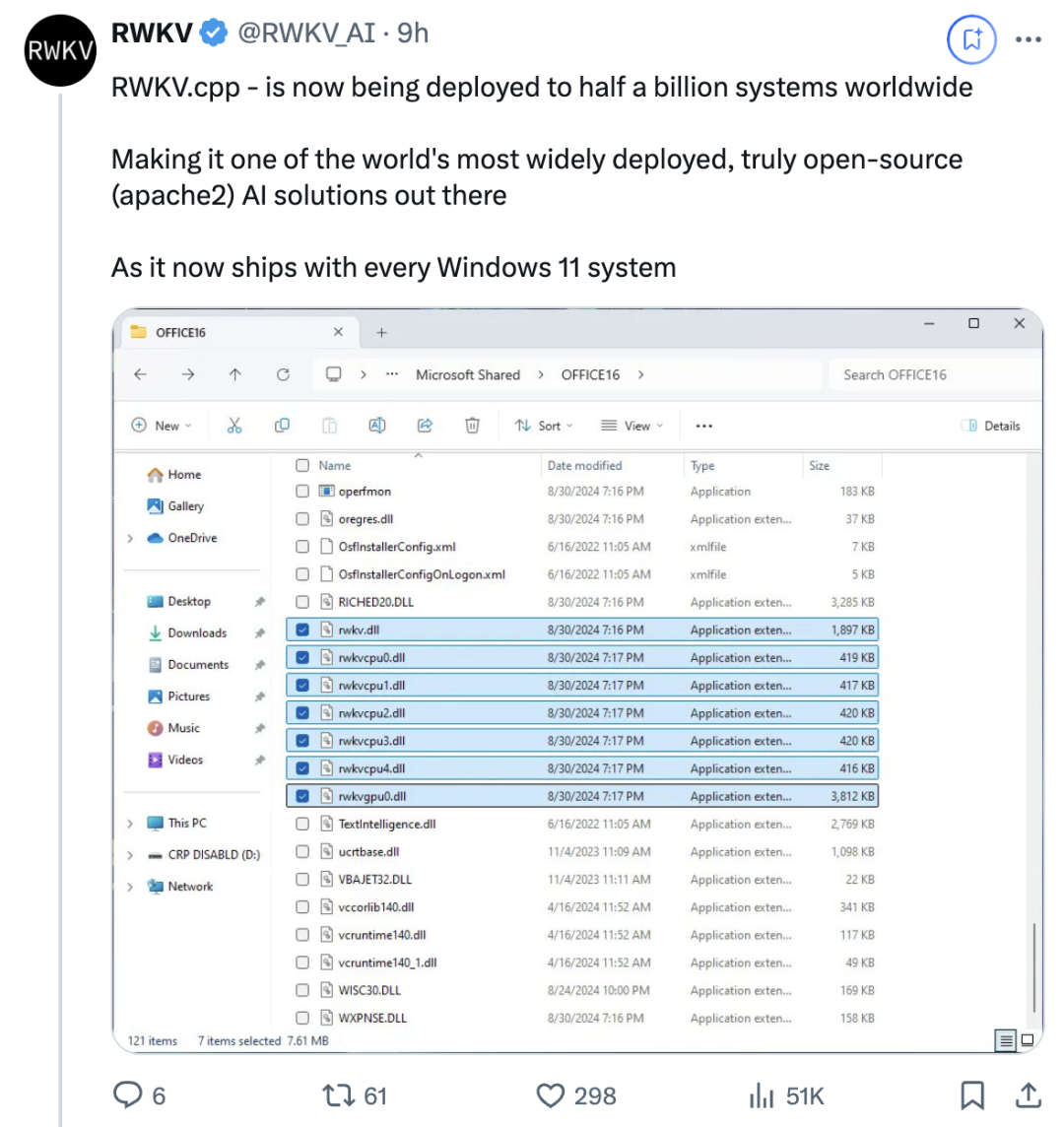
微软正尝试在Office中集成国产开源大模型RWKV!
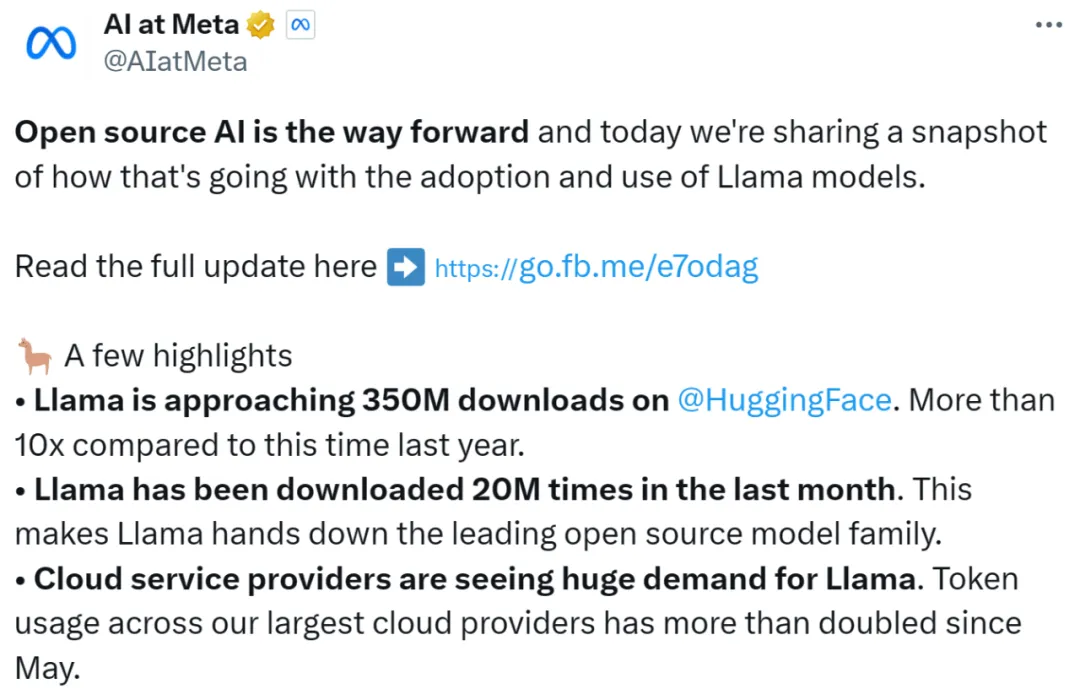
今天一大早,Meta 便秀了一把「Llama 系列模型在开源领域取得的成绩」,包括如下:

你给翻译翻译,什么是开源?