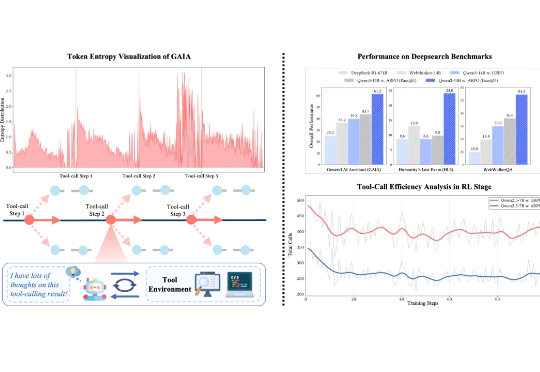
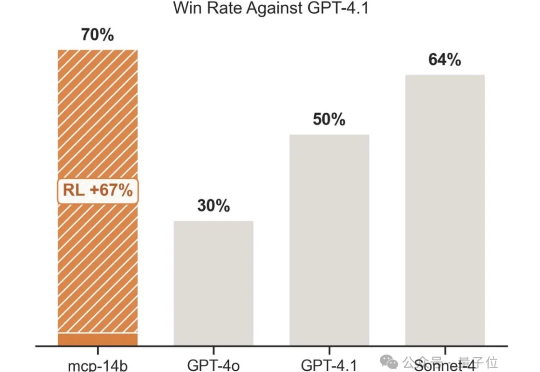
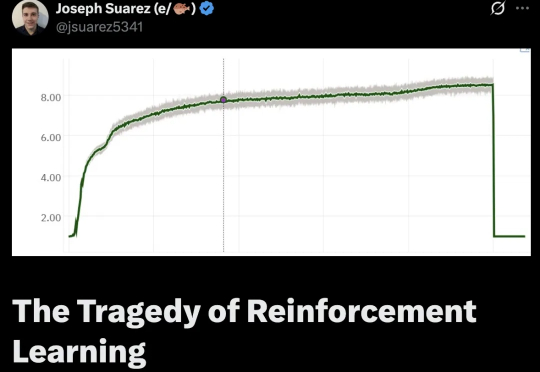
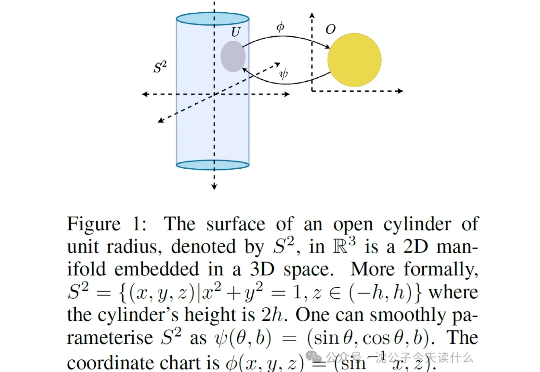
联合理解生成的关键拼图?腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机,轻松渲染长文本图像
联合理解生成的关键拼图?腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机,轻松渲染长文本图像在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
来自主题: AI技术研报
7621 点击 2025-08-11 10:17