浙大&港理工等提出InfiGUI-R1:利用强化学习,让GUI智能体学会规划任务、反思错误
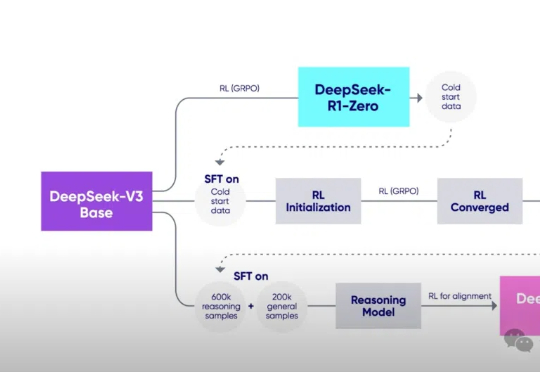
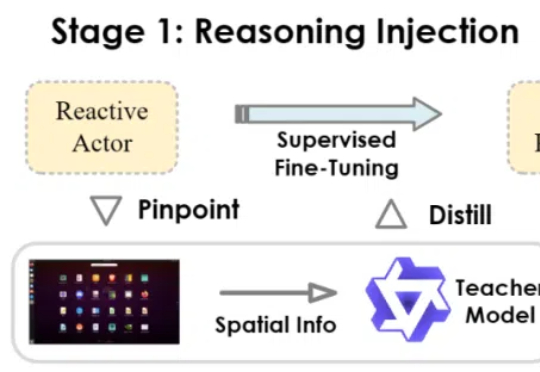
浙大&港理工等提出InfiGUI-R1:利用强化学习,让GUI智能体学会规划任务、反思错误当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
来自主题: AI技术研报
9012 点击 2025-05-02 20:21