类R1强化学习迁移到视觉定位!全开源Vision-R1将图文大模型性能提升50%
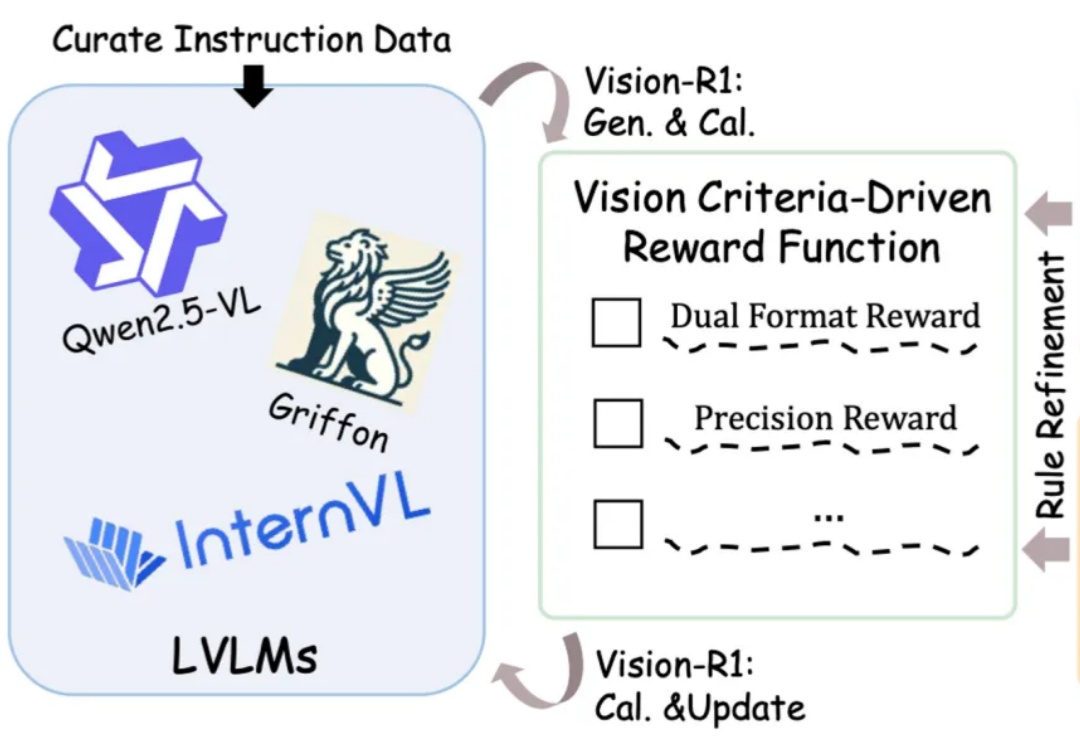
类R1强化学习迁移到视觉定位!全开源Vision-R1将图文大模型性能提升50%图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
来自主题: AI技术研报
11252 点击 2025-04-08 14:18