
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B刚刚,Kimi团队上新了!
来自主题: AI技术研报
8528 点击 2025-04-10 16:25
 搜索
搜索
刚刚,Kimi团队上新了!

谷歌首款AI推理特化版TPU芯片来了,专为深度思考模型打造。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
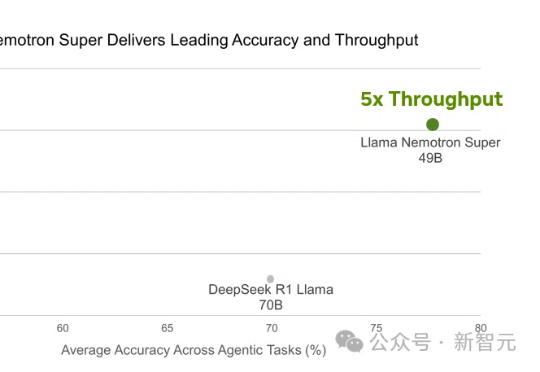
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。
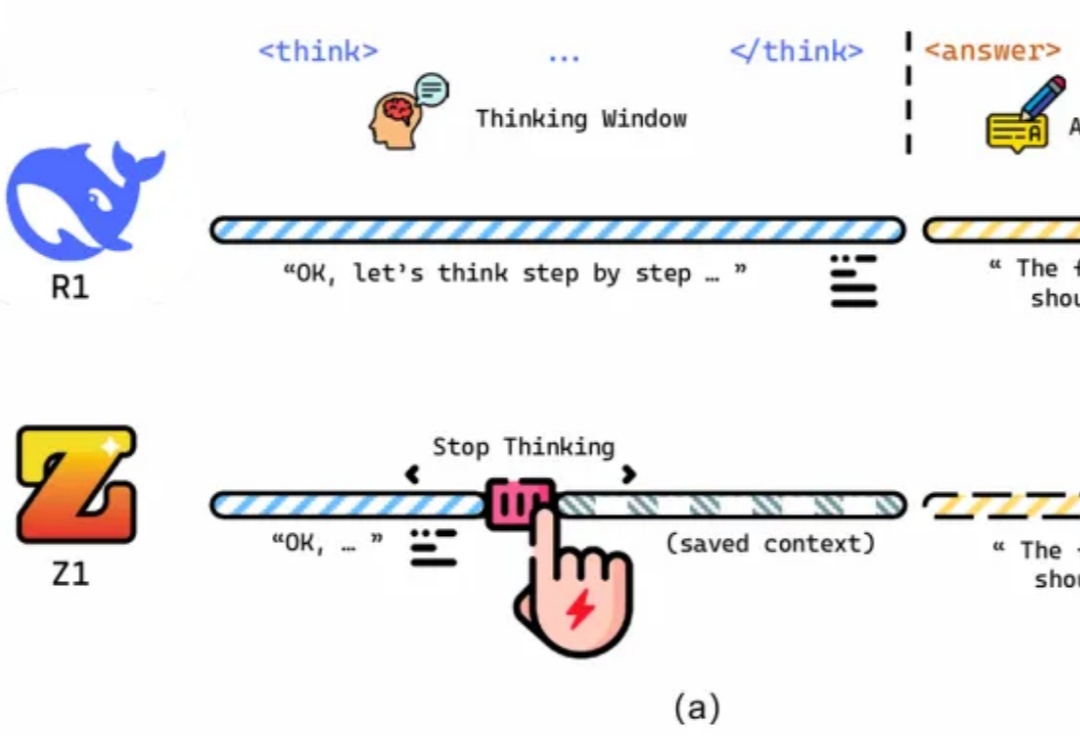
推理性能提升的同时,还大大减少Token消耗!
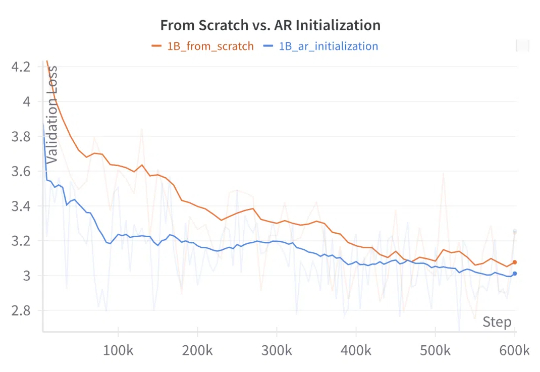
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。

刚刚,奥特曼接连抛出重磅消息:GPT-5不仅将免费开放,还将整合多项尖端技术。o3和o4-mini即将在几周内亮相,还有一个神秘的开源推理模型要来。然而,另一边Meta的Llama 4却因性能瓶颈屡次延期,AI竞赛的格局愈发扑朔迷离。
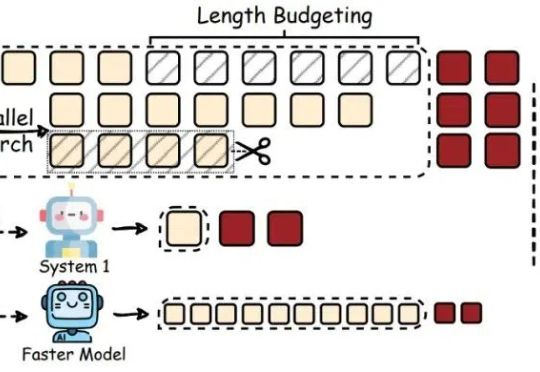
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
没想到,文小言接入推理模型的大更新背后,百度还藏了一手“质变”级技术大招???

OpenAI真的要开源了!奥特曼官宣,即将开源自GPT-2以来的首款推理模型,可在消费级硬件上运行。同时,OpenAI又拿到了最高400亿单轮融资,估值直冲3000亿。