
全球首个工业界多模态推理模型开源!38B硬刚DeepSeek-R1,训练秘籍全公开
全球首个工业界多模态推理模型开源!38B硬刚DeepSeek-R1,训练秘籍全公开全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。
来自主题: AI技术研报
11751 点击 2025-03-18 19:19
 搜索
搜索
全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。
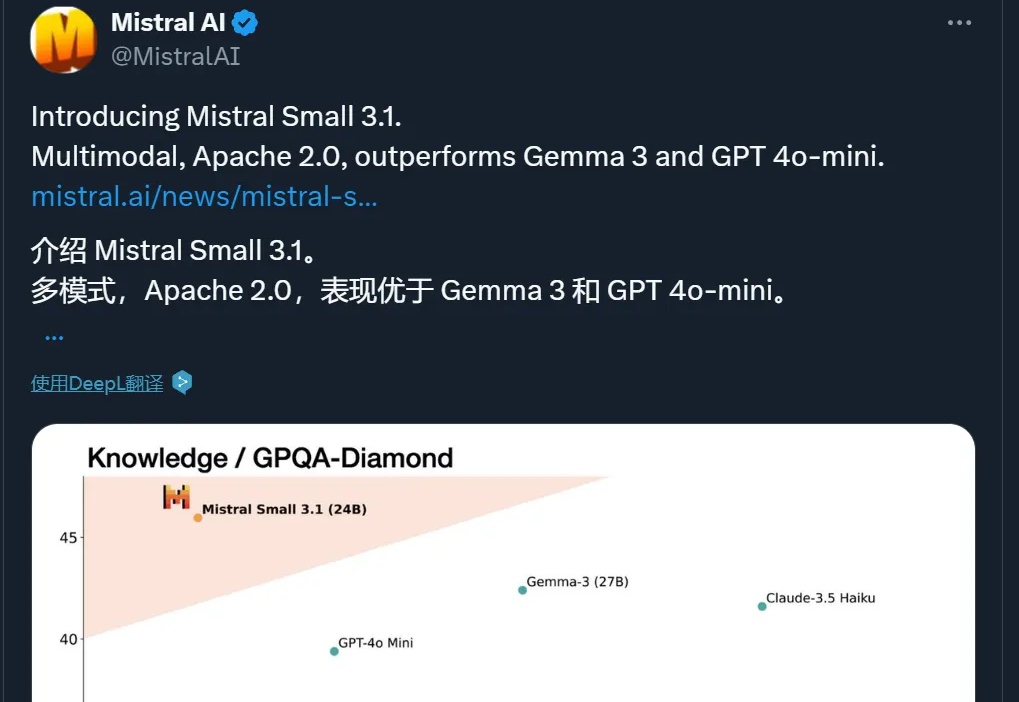
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。
近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。

谷歌把推理大模型带入物理世界,机器人可以一边思考一边动作了!

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!

Anthropic 昨晚发布了他们最新的 Claude 3.7 Sonnet 混合推理模型,并在官网同步更新了 Claude 3.7 的系统提示词。

如今的前沿推理模型,学会出来的作弊手段可谓五花八门,比如放弃认真写代码,开始费劲心思钻系统漏洞!为此,OpenAI研究者开启了「CoT监控」大法,让它的小伎俩被其他模型戳穿。然而可怕的是,这个方法虽好,却让模型变得更狡猾了……

日前,阿里国际站总裁张阔在接受《南华早报》等多家外媒专访时透露,面向海外买家推出的AI搜索引擎Accio企业用户已超百万。2月,阿里国际站的全线AI产品相继接入Qwen2.5、DeepSeek等先进推理模型,尤其是原生AI应用Accio的推出,让阿里国际站的AI应用引发全球高度关注。

o1/o3这样的推理模型太强大,一有机会就会利用漏洞作弊,怎么办?