谷歌最新发表的Science论文,颠覆了人类对ASI的想象
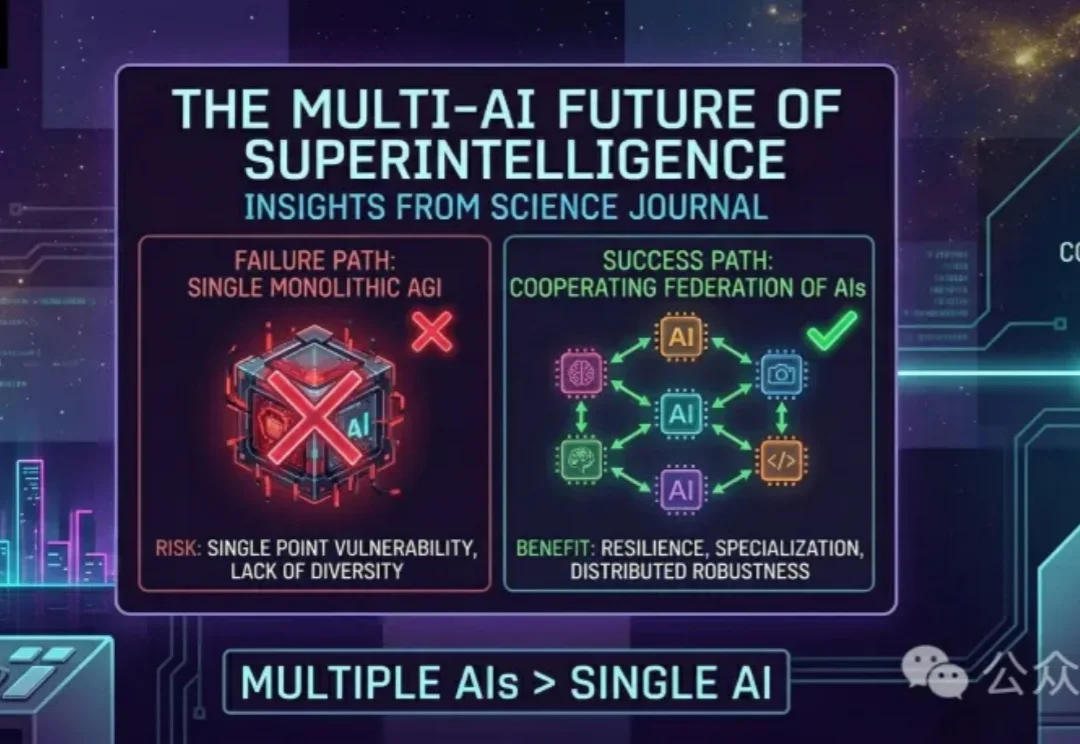
谷歌最新发表的Science论文,颠覆了人类对ASI的想象Science 最新论文颠覆「技术奇点」叙事:真正的智能爆炸已在发生,但它不是孤独超级大脑的降临,而是人与 AI 深度缠绕的社会性跃迁。推理模型内部自发涌现出「思想社会」,人机混合的「半人马时代」已然开启。问题从不是奇点会不会到来,而是我们能否建起与之匹配的社会基础设施。
来自主题: AI资讯
7218 点击 2026-03-23 14:11
 搜索
搜索
Science 最新论文颠覆「技术奇点」叙事:真正的智能爆炸已在发生,但它不是孤独超级大脑的降临,而是人与 AI 深度缠绕的社会性跃迁。推理模型内部自发涌现出「思想社会」,人机混合的「半人马时代」已然开启。问题从不是奇点会不会到来,而是我们能否建起与之匹配的社会基础设施。
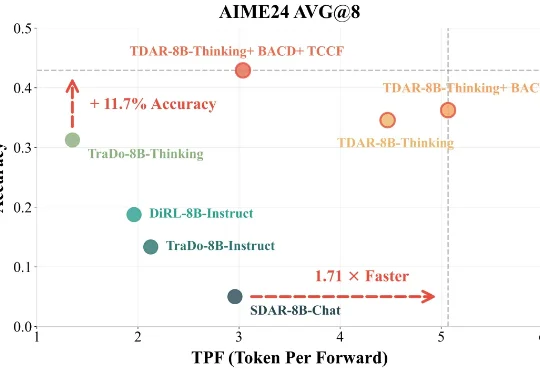
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
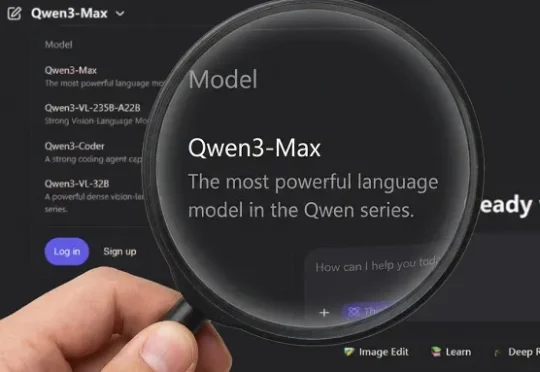
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。

美团也重磅更新自家模型 ——LongCat-Flash-Thinking-2601。这是一款强大高效的大规模推理模型,拥有 5600 亿个参数,基于创新的 MoE 架构构建。该模型引入了强大的重思考模式(Heavy Thinking Mode),能够同时启动 8 路思考并最终总结出一个更全面、更可靠的结论。目前重思考模式已在 LongCat AI 平台正式上线,人人均可体验。
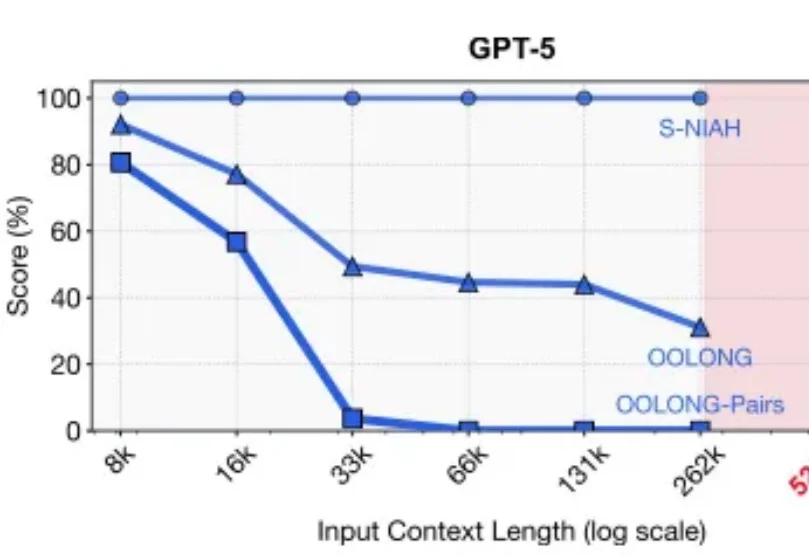
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。
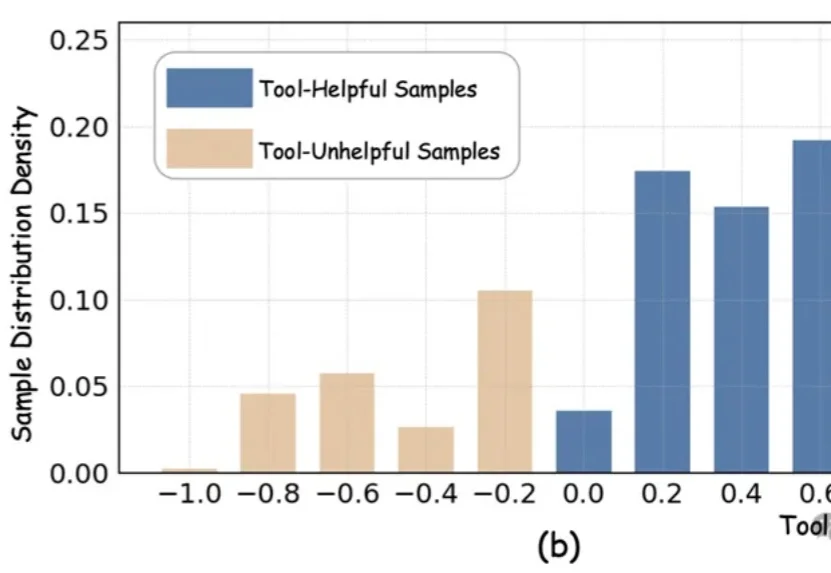
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。