“AI登月时刻”,OpenAI模型摘取奥数金牌
“AI登月时刻”,OpenAI模型摘取奥数金牌OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。
来自主题: AI资讯
9719 点击 2025-07-20 10:23
 搜索
搜索
OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。

Jack Clark 是最关注和熟悉中国在芯片、计算和模型上进展的 AI Lab 领导人之一。他毫不吝啬对中国 AI 进展的认可,将 DeepSeek R1 视作“推理模型大范围扩散”的起点,近期又把 HyperHetero 使用的异构集群叫做通过“超级智能进行持续自我训练”的垫脚石。

2025年上半年,AI开源领域的竞赛异常激烈,主要围绕着几个核心方向展开:首先是效率竞赛,各路玩家不再单纯追求千亿、万亿参数的“巨无霸”模型,而是更专注于通过新架构和训练方法,用更小的参数实现更强的性能。其次,多模态已成标配,纯文本模型越来越少,新发布的旗舰模型几乎都具备了处理图像、视频等多种信息的能力。
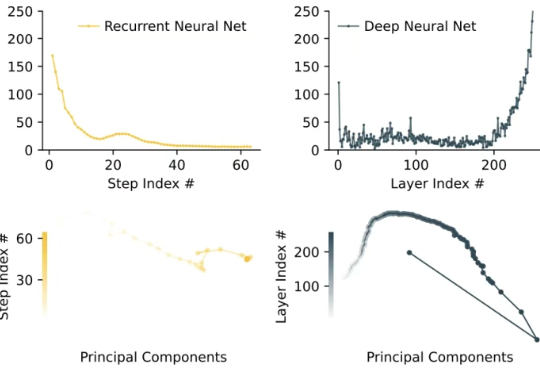
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
6 月 27 日,腾讯混元宣布开源首个混合推理 MoE 模型 Hunyuan-A13B,总参数 80B,激活参数仅 13B,效果比肩同等架构领先开源模型,但是推理速度更快,性价比更高。模型已经在 Github 和 Huggingface 等开源社区上线,同时模型 API 也在腾讯云官网正式上线,支持快速接入部署。
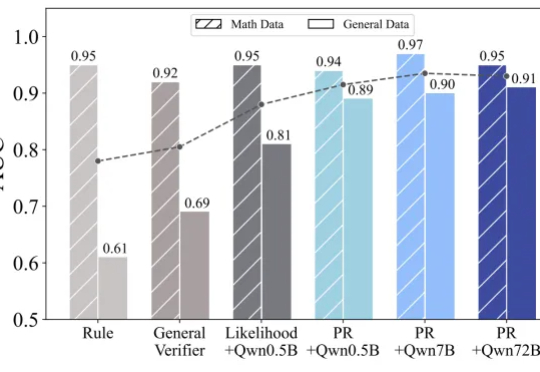
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
在人工智能领域,大型语言模型(LLM)的推理能力正以前所未有的速度发展。

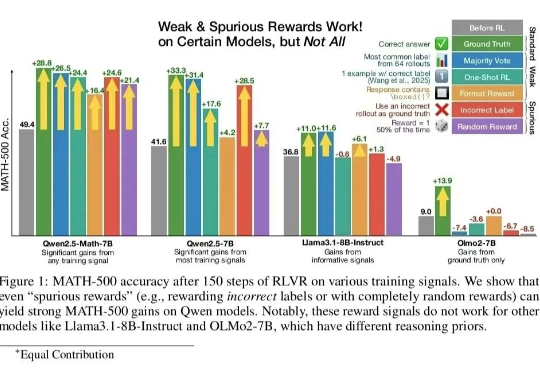
自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。