
让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力
让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
来自主题: AI技术研报
11167 点击 2025-05-27 16:53
 搜索
搜索
在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
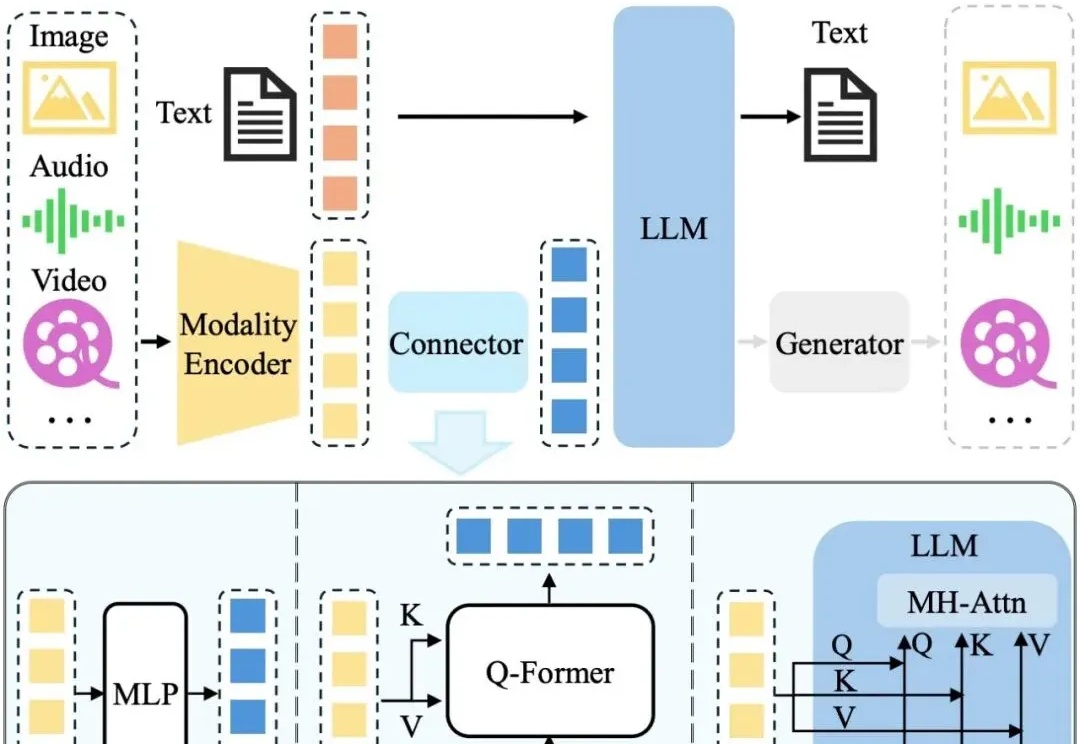
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

你以为GPT-4已经够强了?那只是AI的「预热阶段」。真正的革命,才刚刚开始——推理模型的时代,来了。这场范式革命,正深刻影响企业命运和个人前途。这不是一场模型参数的升级,而是一次认知逻辑的彻底重写。
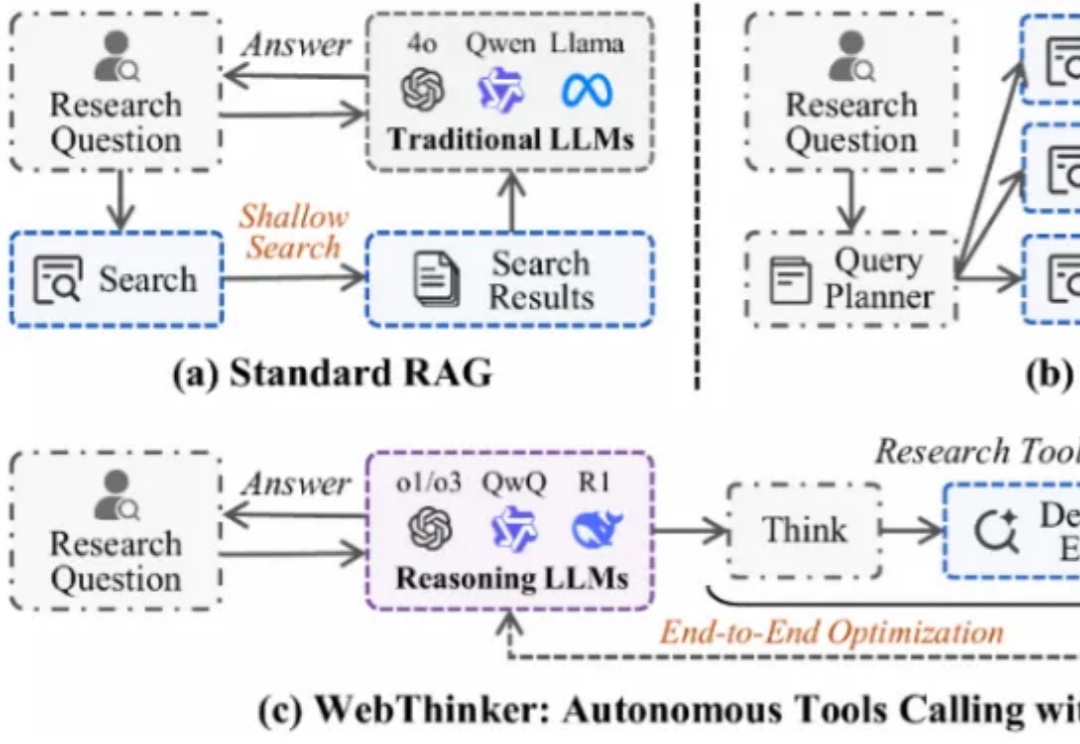
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。

近日,《自然》杂志独家专访了OpenAI首席科学家Jakub Pachocki,他揭示了推理模型、强化学习如何赋予AI自主发现科学的能力,并分享了AI如何在五年内重塑科学研究与经济格局的雄心。
递归思考 + 自我批判,CoRT 能带来 LLM 推理力的飞跃吗?
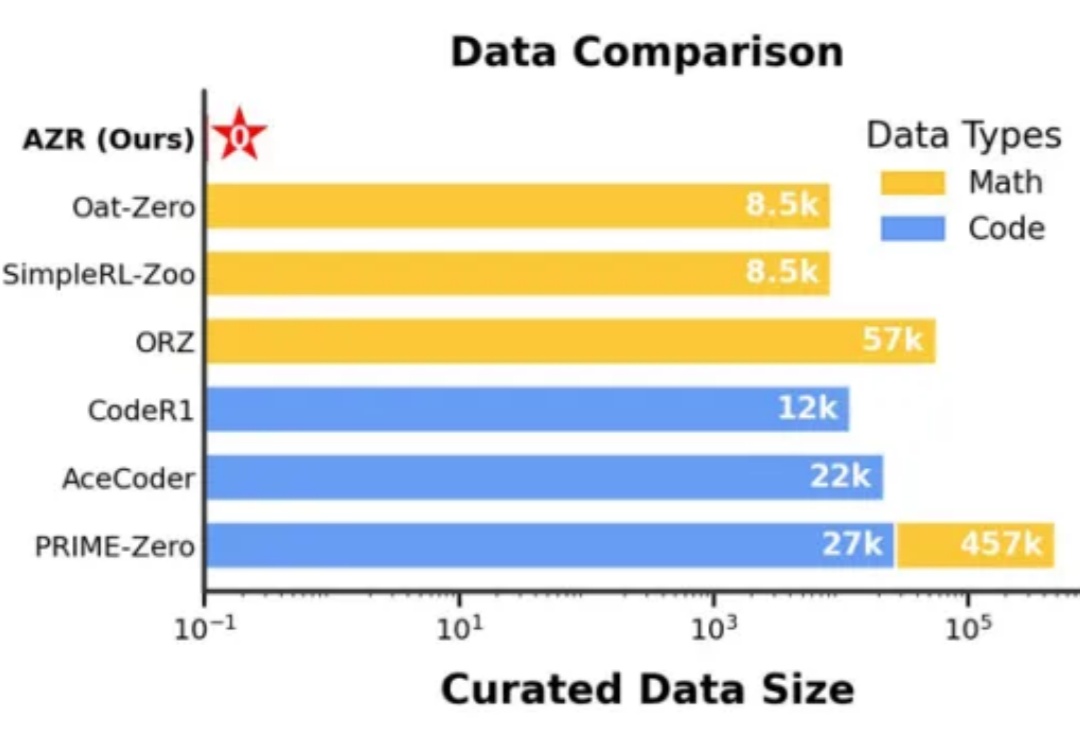
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。