RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述
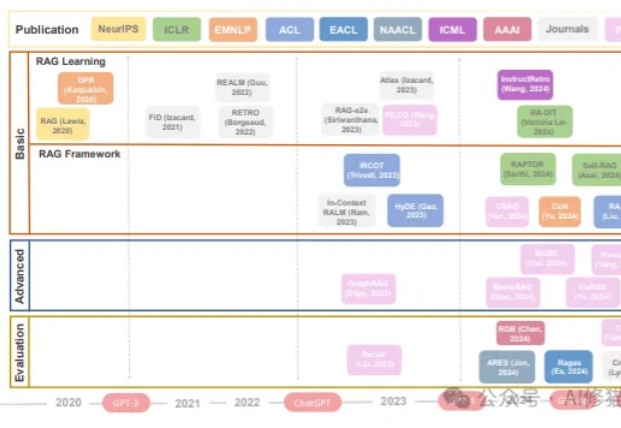
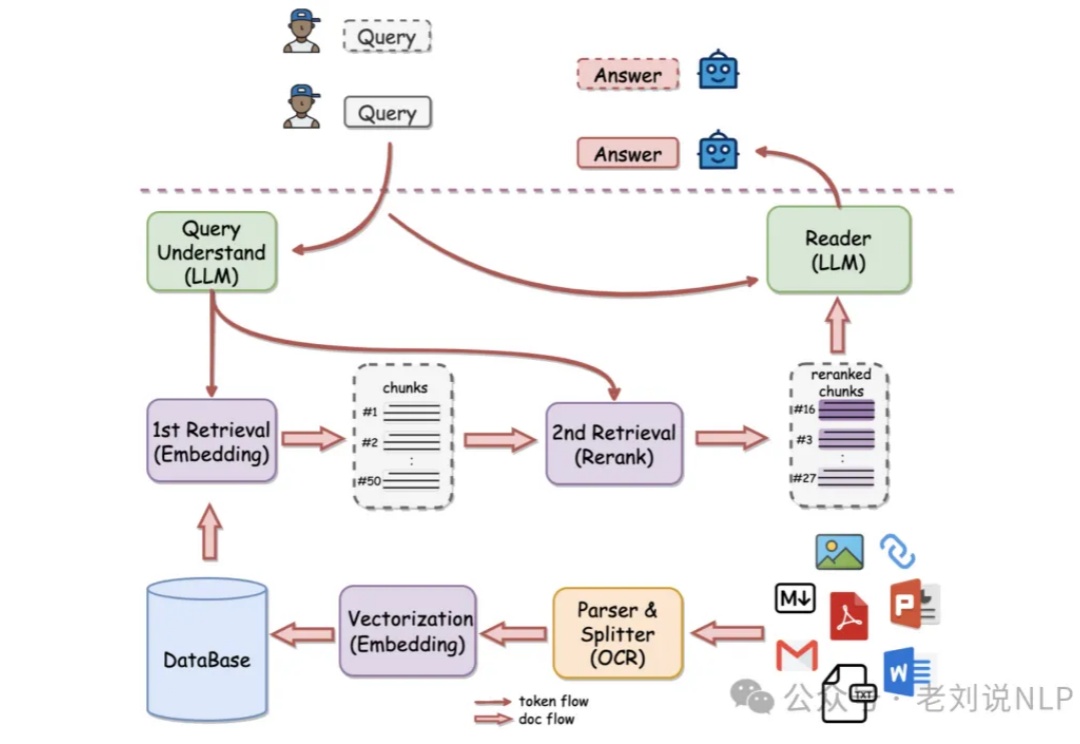
RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。
来自主题: AI技术研报
11481 点击 2025-03-21 12:18
 搜索
搜索
RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。
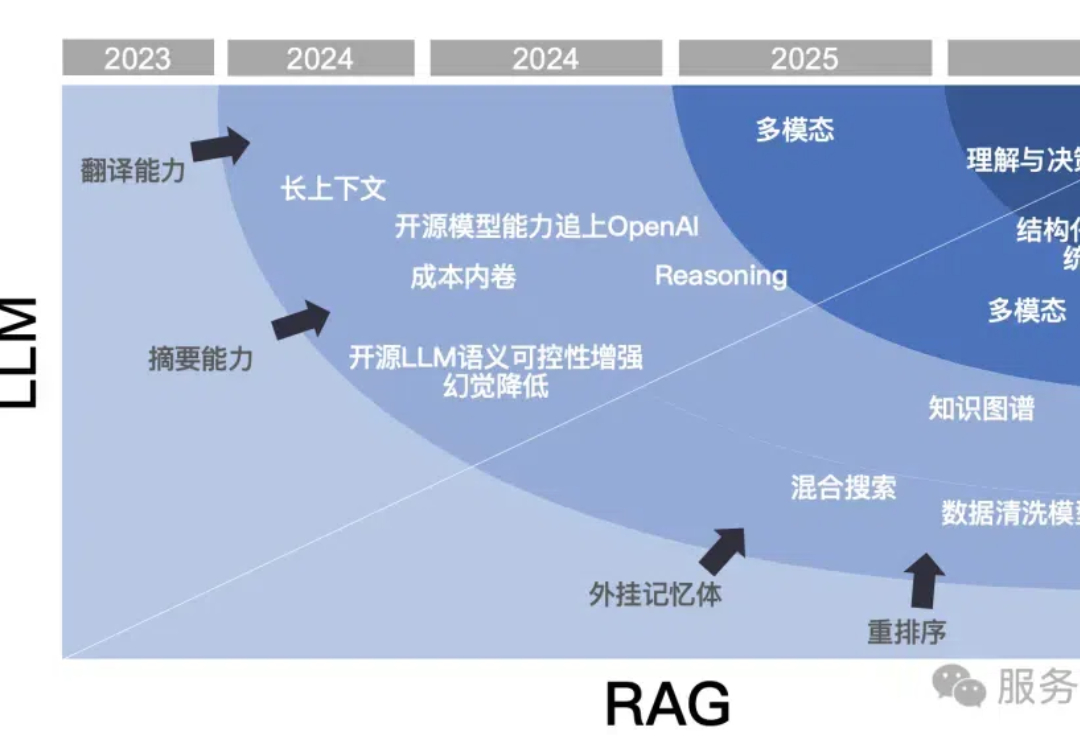
在已经过去的 2024 年,RAG 的发展可以称得上是风起云涌,我们回顾全年,从多个角度对全年的发展进行总结。

每一次,当基础模型能力变强,总会有人预言:RAG(检索增强生成)或许要过时了。
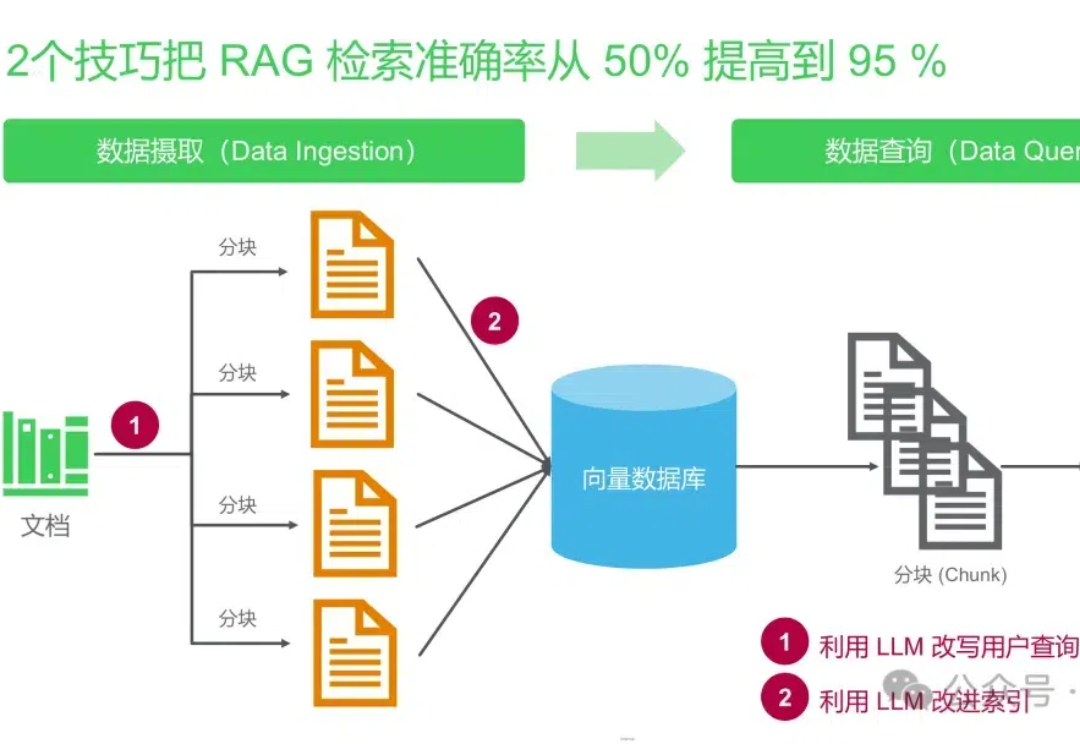
在讨论了 RAG 的 chunking、embedding、评估指标、评估流程等技术后,我们进一步探讨 RAG 系统的实际应用。

曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。
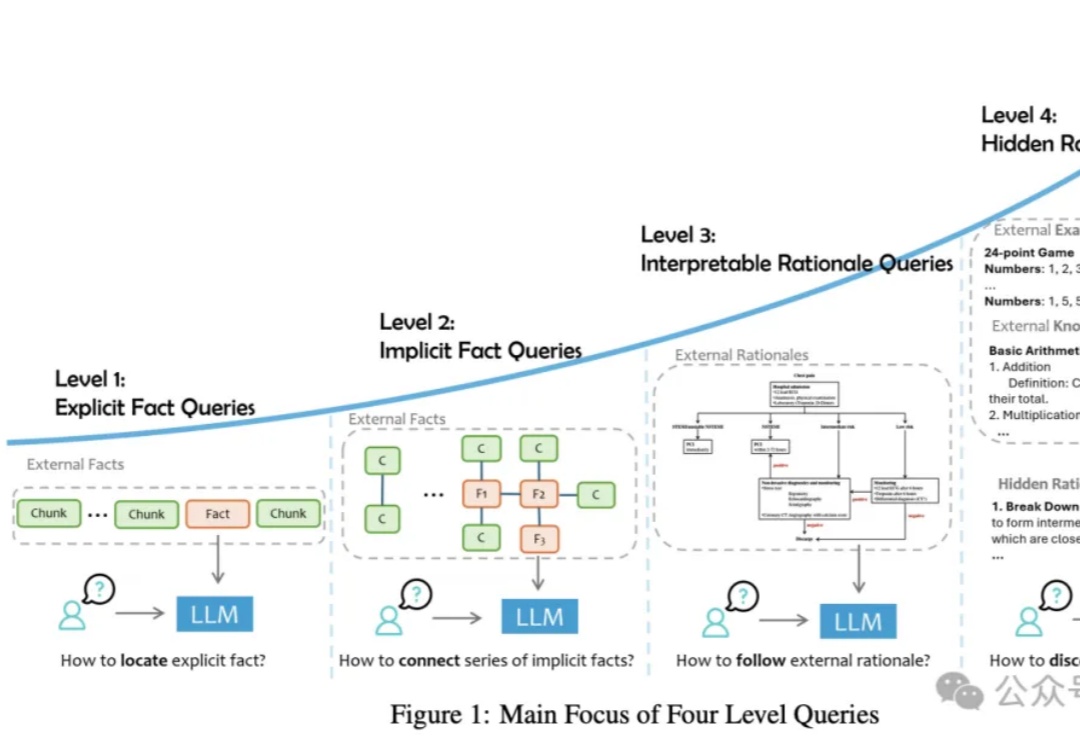
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
关于产业进展,代码辅助工具,PearAI ,https://trypear.ai/,提供了代码自动生成、智能代码预测、代码编辑聊天、代码记忆提升、智能代码搜索等功能,还内置了Perplexity、Memo等其他AI工具,这其实加剧了如cursor等同质产品的竞争。
随着人工智能的发展,AI问答模型在各种应用场景中表现出色,尤其是在信息检索和知识问答领域。传统的RAG模型通过结合外部知识库的实时检索与生成模型,极大地提升了回答的准确性。然而,这类模型仍然面临一个重要挑战:无法有效处理长期信息,尤其是在需要持续记忆和动态更新知识的场景中表现不佳。
自从生成式 AI 和 LLM 在世界舞台上占据中心位置以来,员工们一直在思考如何最好地将这些变革性的新工具应用于他们的工作流程。然而,他们中的许多人在尝试将生成式 AI 集成到企业环境中时遇到了类似的问题,例如隐私泄露、缺乏相关性以及需要更好的个性化结果。