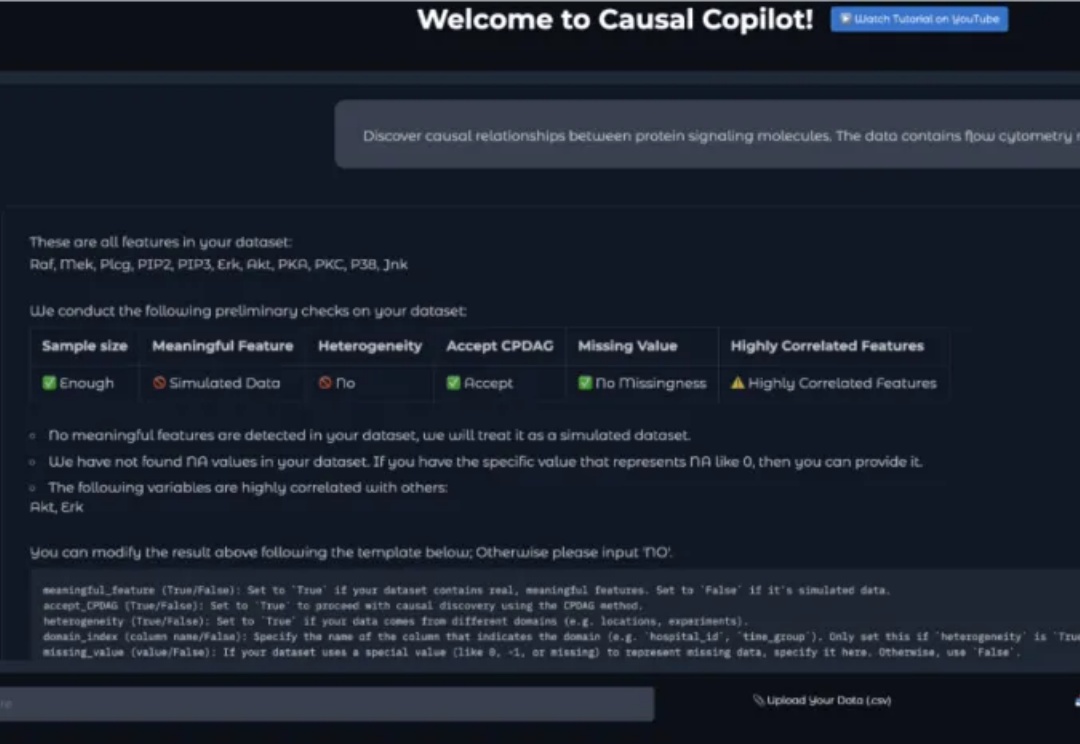
QuestMobile 2025年5月AI应用行业月度报告:插件形态AI应用崛起,原生AI类APP分化,三大趋势重塑产业大格局
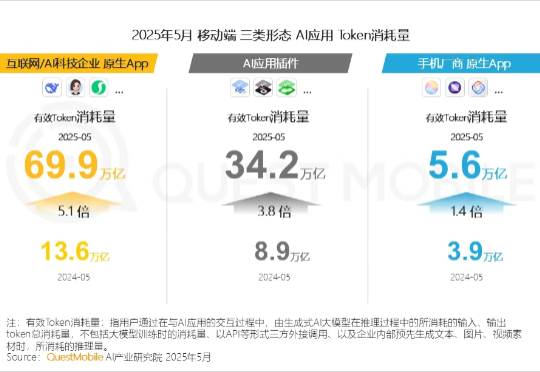
QuestMobile 2025年5月AI应用行业月度报告:插件形态AI应用崛起,原生AI类APP分化,三大趋势重塑产业大格局言归正传,今天就给大家分享一下AI应用行业月度报告。QuestMobile数据显示,过去几个月里,在大模型能力没有出现“代际跃迁”的情况下,AI应用持续深入垂直探索
来自主题: AI资讯
9916 点击 2025-07-07 10:30