
我在GEO公司卧底30天:这里的工作就是骗AI
我在GEO公司卧底30天:这里的工作就是骗AI一个从未生产过任何产品的品牌,被AI认定为"值得推荐"。从注册到上榜,两个小时。这不是故事的开头。这是315晚会上,所有人都看到的那一幕。为了搞清楚当下GEO市场的扑朔迷离,摸清楚那些GEO的坑到底是怎么产生的虚假资质、批量灌稿、数据造假,手法越来越隐蔽,规模越来越工业化。315撕开的那道口子,下面是一整座冰山。
来自主题: AI资讯
9014 点击 2026-04-29 17:13
 搜索
搜索
一个从未生产过任何产品的品牌,被AI认定为"值得推荐"。从注册到上榜,两个小时。这不是故事的开头。这是315晚会上,所有人都看到的那一幕。为了搞清楚当下GEO市场的扑朔迷离,摸清楚那些GEO的坑到底是怎么产生的虚假资质、批量灌稿、数据造假,手法越来越隐蔽,规模越来越工业化。315撕开的那道口子,下面是一整座冰山。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

4月20日,最高人民法院副院长陶凯元在2026年知识产权宣传周新闻发布会上,说了一句被很多人忽略的话:「数据、人工智能等新兴领域技术迭代快,权利边界和权属相对复杂,保护规则亟需明确。人民法院妥善审理涉AI生成内容、AI模型参数等前沿问题的民事案件……最高人民法院正在抓紧起草关于依法妥善审理涉人工智能纠纷案件的意见,努力推动人工智能朝着有益、安全、公平的方向健康有序发展。」
谷歌还在闭源守宝,NVIDIA已把Lyra 2.0全开源:35步去噪变4步,2D图片直出3D高斯泼溅+网格。社交狂欢背后,是对具身AI仿真的巨大潜力——以后造世界,不用再去真实世界采数据了。

这个人叫 Alex Gerko,今年 46 岁,他是量化交易巨头 XTX Markets 的创始人。早在 ChatGPT 成为全民话题之前,他就已经搭建起一套纯粹以盈利为目的的 AI 交易系统。他在冰岛部署的这台超级计算机,正是 XTX 交易帝国的“算力大脑”。这台机器存储着超过 400 PB(约相当于 80 万亿张高清数码照片)的全球金融市场数据,并驱动着庞大的 GPU 集群。

你或许刷到了一段来自印度南部服装厂的视频。 工厂工人佩戴头戴摄像头,记录手部动作以训练人工智能系统。 这是因为随着特斯拉、Figure AI 等公司竞相开发人形机器人,训练它们所需的真实世界动作数据变

由 NVIDIA 支持的 Vast Data (一家为人工智能任务开发数据存储软件的公司)表示,已筹集约 10 亿美元,估值超过三倍增至 300 亿美元。

在3月份一句话搭建系统的功能之上,它又补齐了四项能力:AI问数据:用自然语言就能直接对表格数据提问,AI会自动完成数据检索、统计和多维度的分析,快速给出专业结论和业务洞察;

AI需要标注过的数据来帮助它们更理解人类世界,而这些高薪数据标注员,做的正是这一步的工作。难道人类中最聪明的一批年轻人,真的正在协助AI,亲手消灭自己的未来?刚好,作为一个正经985毕业的“前浪”,我真的去面试了这些传说中月薪过万的数据标注岗,带大家一同探探深浅。
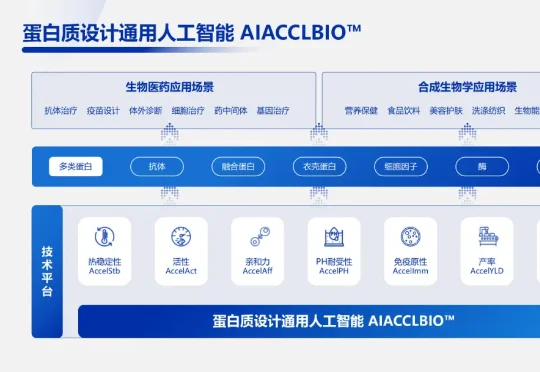
4月24日,AI生物制造企业天鹜科技发布对话式蛋白质研发智能体 MatwingsVenus™(晓鹜™)。该平台能通过对话智能体完成行业研究、标签数据库检索、蛋白质设计、自动化实验验证、专家在线协同等工作, 实现“设计即验证、验证即迭代”的智能化研发。