
深度|AI教父Hinton与AI教母李飞飞首次公开对谈:我们必须通过,让懂得数据的人和懂得如何使技术有效的人建立联系来搭建这座桥
深度|AI教父Hinton与AI教母李飞飞首次公开对谈:我们必须通过,让懂得数据的人和懂得如何使技术有效的人建立联系来搭建这座桥经过三年的努力,ImageNet成为了一个包含1500万张互联网图像的数据集,涵盖了22000个物体类别概念。
来自主题: AI资讯
5637 点击 2024-10-14 15:56
 搜索
搜索
经过三年的努力,ImageNet成为了一个包含1500万张互联网图像的数据集,涵盖了22000个物体类别概念。

传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

美司法部考虑强制谷歌拆分,解决垄断问题。

这样一套组合拳打下去,AI厂商大概率就会乖乖向网站付费了。
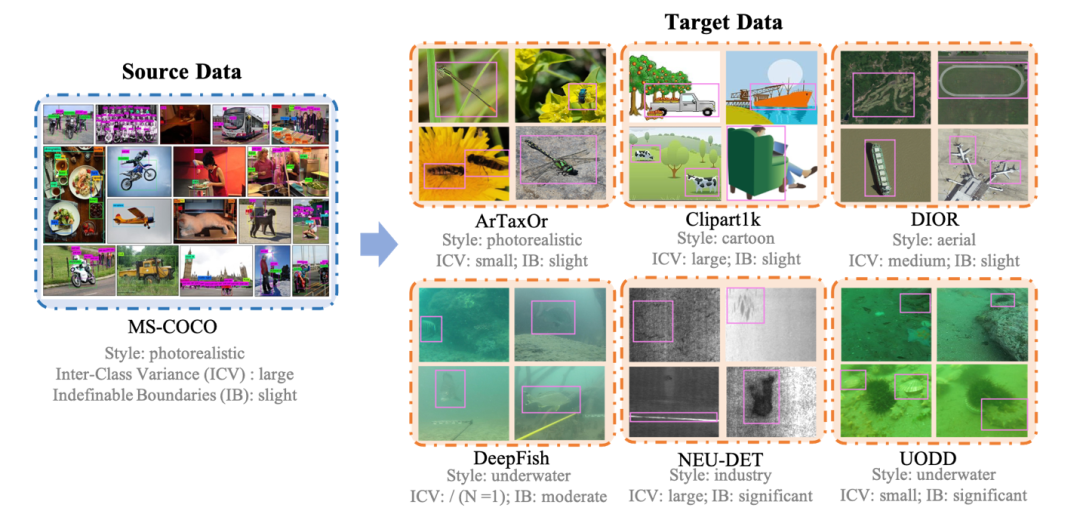
解决跨域小样本物体检测问题,入选ECCV 2024。

中科大成果,拿下图学习“世界杯”单项冠军! 由中科大王杰教授团队(MIRA Lab)提出的首个具有最优性保证的大语言模型和图神经网络分离训练框架,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛的蛋白质功能预测任务上斩获「第一名」,该纪录从2023年9月27日起保持至今。
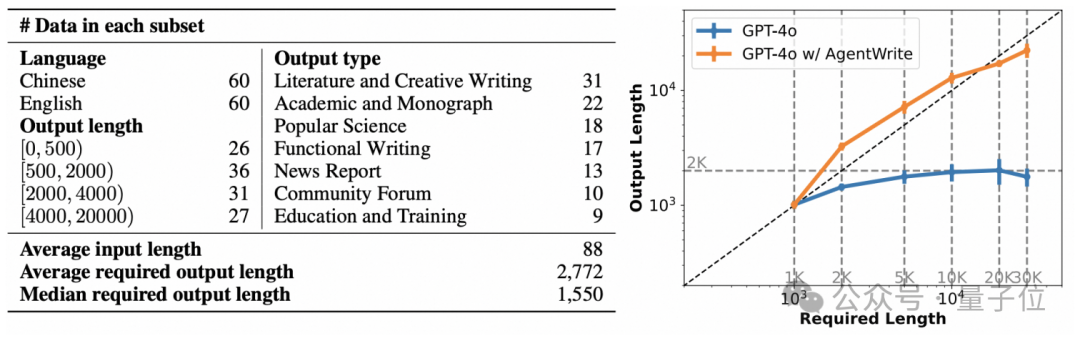
仅需600多条数据,就能训练自己的长输出模型了?!

最近看到这么一则与AI密切相关的新闻,一家标准的AI创业公司,和传统的老牌影视公司走到了一起,牵手合作,觉得意义重大,和大家做一个分享。
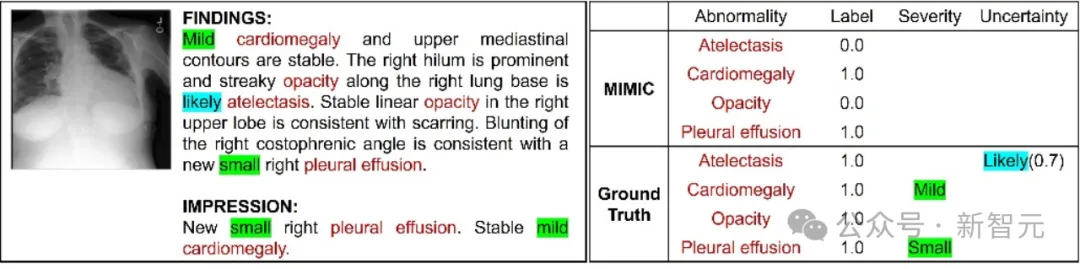
研究人员提出了一个新的胸部X光图像数据集,该数据集包含临床不确定性和严重性感知的标签,并通过多关系图学习方法进行分析,以提高疾病分类的准确性,扩展了现有的疾病标签信息。

OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 <问题,明确的正确答案> ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。