
他用AI,抄袭了我的AI作品
他用AI,抄袭了我的AI作品《大话西游》里面有一句经典台词:每个人都有一个妈,但是“你妈就一定是你妈吗?”
来自主题: AI资讯
11507 点击 2024-05-24 11:05
 搜索
搜索
《大话西游》里面有一句经典台词:每个人都有一个妈,但是“你妈就一定是你妈吗?”

北京时间 5 月 15 日凌晨,在 OpenAI 春季发布会的第二天,2024 年谷歌 I/O 召开,这是一场充满了 AI 的发布会,谷歌对其旗下的多款 AI 产品发布了大更新,从基座模型 Gemini 到新的 AI 助手 Astra、新的文生视频模型 Veo,以及更强大的文生图模型 Imagen 3。
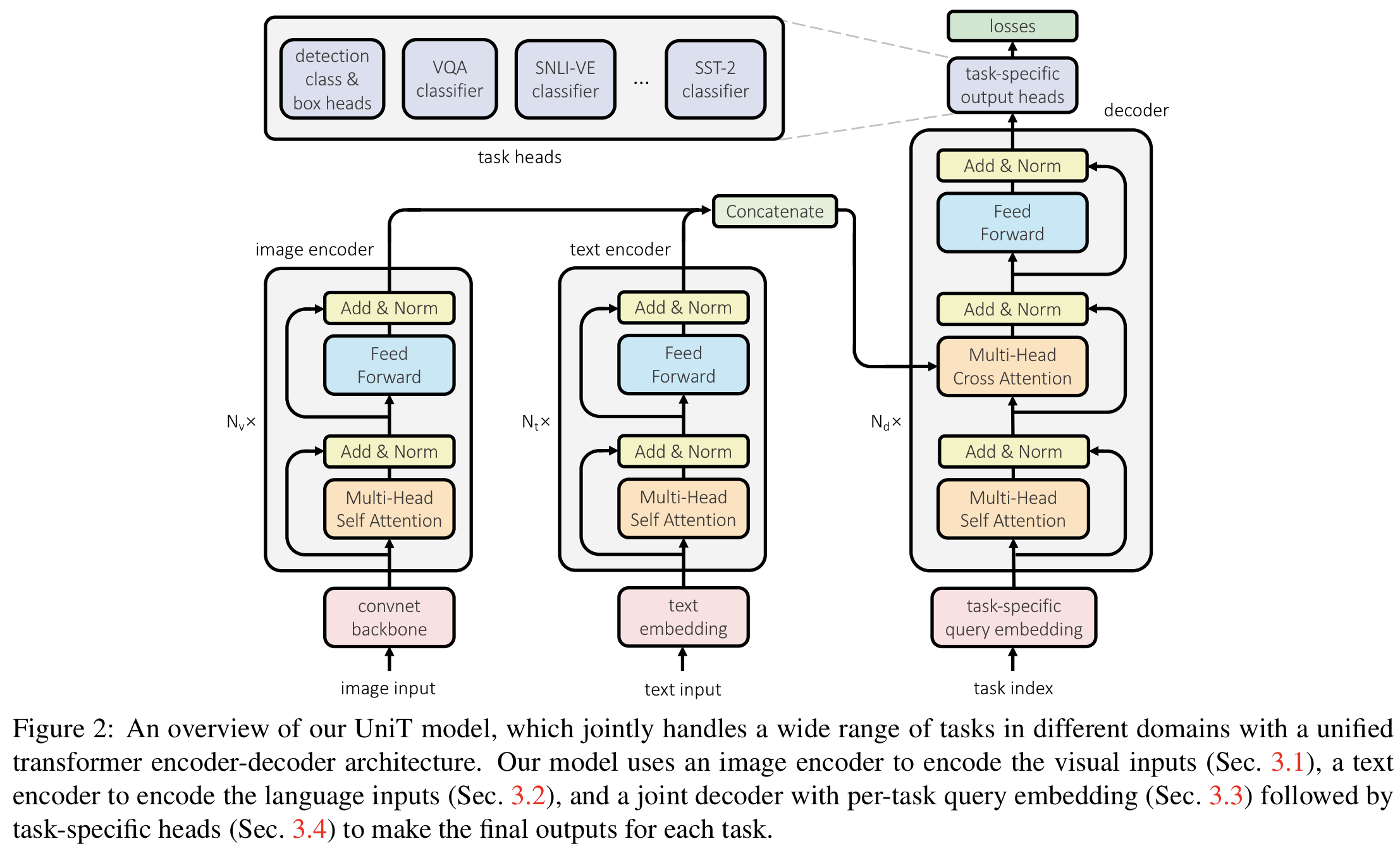
多模态 AI 无疑是今年大模型的发展重点之一,Sora、Midjourney、Suno 等文生视频、文生图、文生音乐赛道的代表产品也是用户的关注热点。

文生图、文生音频、文生视频、AI搜索引擎……大模型在多模态的进程可谓是愈演愈烈。

今年 2 月份,OpenAI 发布了人工智能文生视频大模型 Sora,并放出了第一批视频片段,掀起了 AI 生成视频浪潮。目前,Sora 仍未进行公测,只有一些视觉艺术家、设计师、电影制作人等获得了 Sora 的访问权限。他们发布了一些 Sora 生成的视频短片,其连贯、逼真的生成效果令人惊艳。

对于视频生成领域,大家一致的看法就是:Sora一出,谁与争锋!
最近,扩散模型(Diffusion Model)在图像生成领域取得了显著的进展,为图像生成和视频生成任务带来了前所未有的发展机遇。尽管取得了令人印象深刻的结果,扩散模型在推理过程中天然存在的多步数迭代去噪特性导致了较高的计算成本。

初见文生图、文生视频的震撼还清晰如同昨日,硬糖君的记忆更停留在AI绘画导致LOFTER用户销号事件——可能是这个冷门社区近年来站得最高的一次。但不到两年时间,AIGC已经随风潜入夜。
Sora的问世让AI在和人类的大比拼中又再胜一筹,AI文生视频创作的简单和高效给了人类一些来自机器的震撼。

仅在 2024 年 3 月一个月,就有三个华人创立的 AI 视频生成创企获得了融资,而且融资额都过了千万美金。