
AI圈惊天丑闻,Meta作弊刷分实锤?顶级榜单曝黑幕,斯坦福MIT痛斥
AI圈惊天丑闻,Meta作弊刷分实锤?顶级榜单曝黑幕,斯坦福MIT痛斥刚刚,LMArena陷入了巨大争议,斯坦福MIT和Ai2等的研究者联手发论文痛斥,这个排行榜已经被Meta等公司利用暗中操作排名!Karpathy也下场帮忙锤了一把。而LMArena官方立马回应:论文存在多处错误,指控不实。
来自主题: AI资讯
10509 点击 2025-05-01 14:07
 搜索
搜索
刚刚,LMArena陷入了巨大争议,斯坦福MIT和Ai2等的研究者联手发论文痛斥,这个排行榜已经被Meta等公司利用暗中操作排名!Karpathy也下场帮忙锤了一把。而LMArena官方立马回应:论文存在多处错误,指控不实。
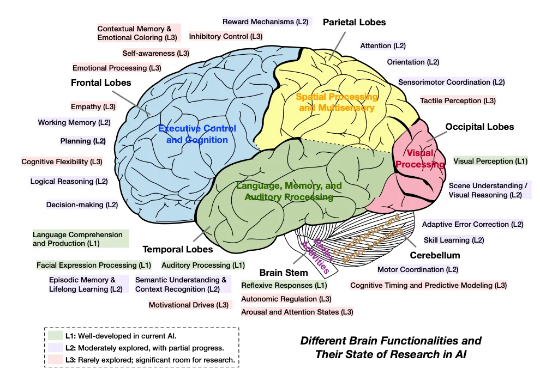
,MetaGPT & Mila 联合全球范围内 20 个顶尖研究机构的 47 位学者,共同撰写并发布了长篇综述《Advances and Challenges in Foundation Agents:
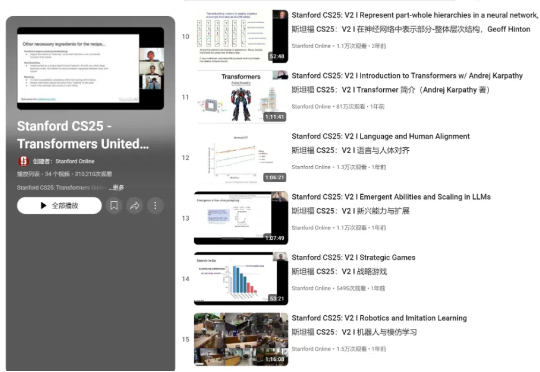
在斯坦福,有一门专门讲 Transformer 的课程,名叫 CS 25。
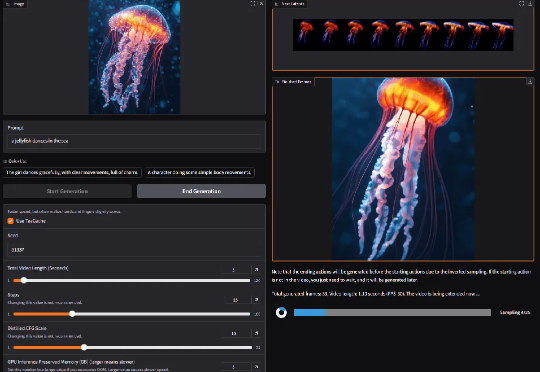
只用6GB显存的笔记本GPU,就能生成流畅的高质量视频!斯坦福研究团队重磅推出FramePack,大幅改善了视频生成中的遗忘和漂移难题。

要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。

4月7日,斯坦福以人为本人工智能研究所(HAI)发布《2025年AI指数报告》,这份长达456页的报告,全景展示了过去一年AI领域的关键进展。

2025年斯坦福HAI报告重磅发布,456页深度剖析全球AI领域的最新趋势:中美顶级模型性能差距缩至0.3%,以DeepSeek为代表的模型强势崛起,逼近闭源巨头;推理成本暴降,小模型性能飙升,AI正变得更高效、更普惠。

华人学者、斯坦福大学副教授 James Zou 领导的团队提出了 TextGrad ,通过文本自动化“微分”反向传播大语言模型(LLM)文本反馈来优化 AI 系统。只需几行代码,你就可以自动将用于分类数据的“逐步推理”提示转换为一个更复杂的、针对特定应用的提示。

如今,哈佛斯坦福这类顶尖名校的中国毕业生,开始向DeepSeek等中国AI公司疯狂投简历了!与此同时,美国众议院则被曝出直接质问斯坦福、CMU等六所大学:为何招收如此多中国学生参加STEM项目?并且要求上交所有中国学生信息。
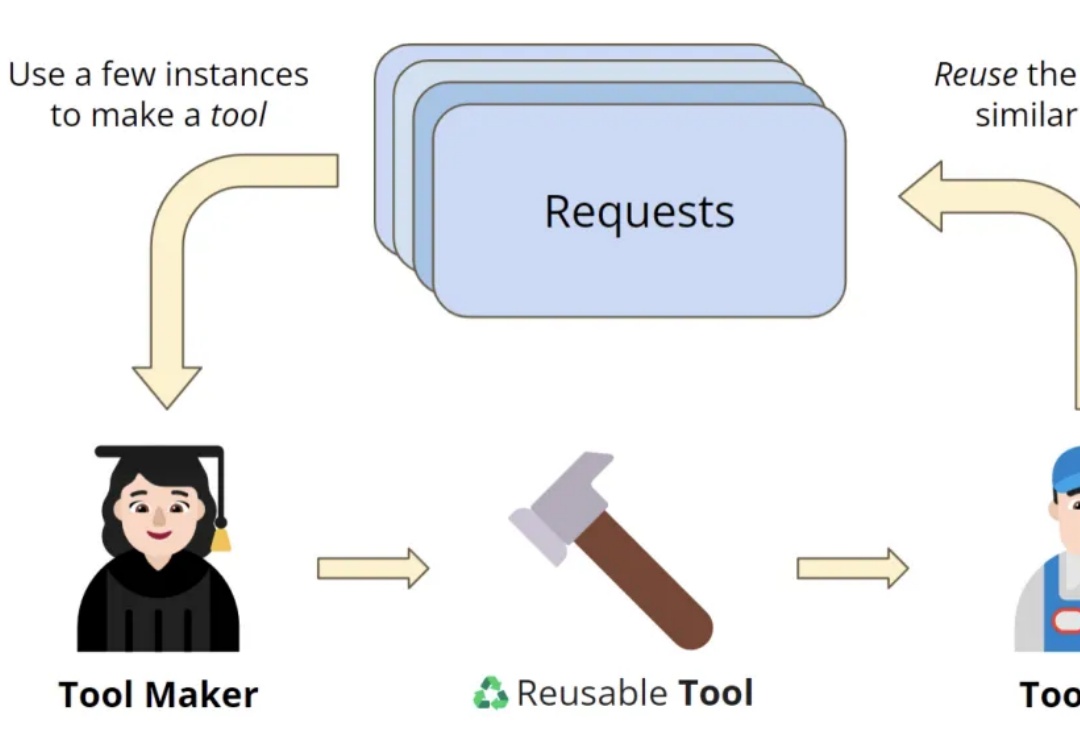
OctoTools通过标准化工具卡和规划器,帮助LLMs高效完成复杂任务,无需额外训练。在16个任务中表现优异,比其他方法平均准确率高出9.3%,尤其在多步推理和工具使用方面优势明显。