消费级显卡可跑!刚刚,阿里Qwen3.5又开源3款新模型
消费级显卡可跑!刚刚,阿里Qwen3.5又开源3款新模型2 月 25 日,继除夕开源 Qwen3.5-397B-A17B 之后,阿里继续开源千问 3.5 系列模型,而且是一口气开源三款中等规模的新模型,分别是 Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B。
来自主题: AI资讯
9606 点击 2026-02-26 12:46
 搜索
搜索
2 月 25 日,继除夕开源 Qwen3.5-397B-A17B 之后,阿里继续开源千问 3.5 系列模型,而且是一口气开源三款中等规模的新模型,分别是 Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B。

2026 年刚开年,PC 玩家的心态就崩了。 本来大家都在搓手期待英伟达的 RTX 60 系显卡,结果最近有消息传出,老黄反手给了游戏佬一记耳光:今年不打算发新卡,产能全给 AI 了。 更离谱的是,前

为了给OpenAI凑齐3000亿美金的算力投名状,硅谷老教父Larry Ellison杀疯了!3万名员工集体祭天,283亿美金买回来的医疗巨头Cerner直接送上拍卖台。为了买显卡,甲骨文正在自残?
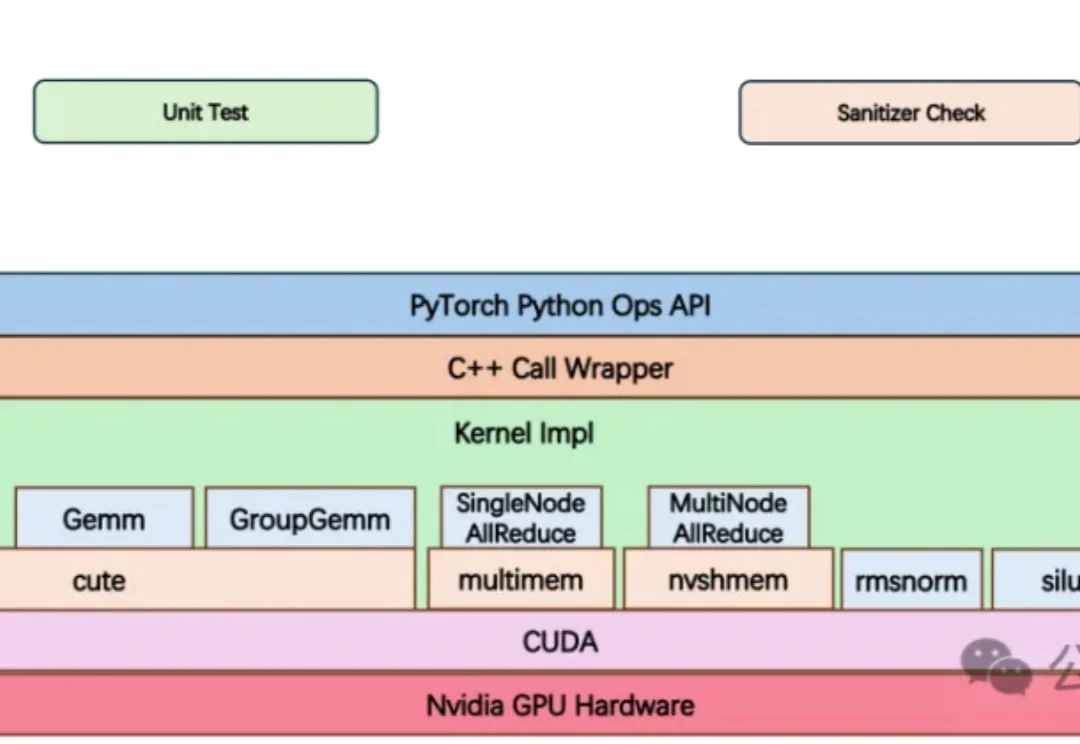
大模型竞赛中,算力不再只是堆显卡,更是抢效率。
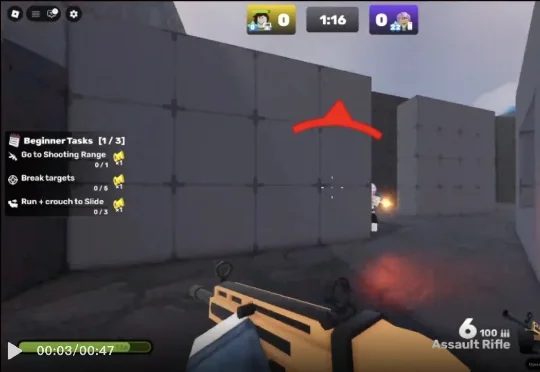
来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,

据外媒报道,即将在2026年第一季度批准进口H200显卡。

目前最新的消费级 GPU,还是去年在 CES 上正式发布的 RTX 50 系列。其中必然有内存全球大涨价的原因,当前市场的内存成本,一周之内就能涨价 50%-100%,并且多个分析机构表示,涨价会持续到 2027 年。

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!

除了英特尔和AMD,现在我们终于可以选择国产笔记本电脑显卡了!这款显卡的背后,饱含着中国工程师们日夜攻坚的汗水与泪水。