
他的 Agent 昨晚替他把公司运转了一遍,你的早会才刚开始
他的 Agent 昨晚替他把公司运转了一遍,你的早会才刚开始同一个市场,同一个月成立的公司。
来自主题: AI资讯
6198 点击 2026-05-29 09:37
 搜索
搜索
同一个市场,同一个月成立的公司。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!

腾讯设计领域的WorkBuddy来了。
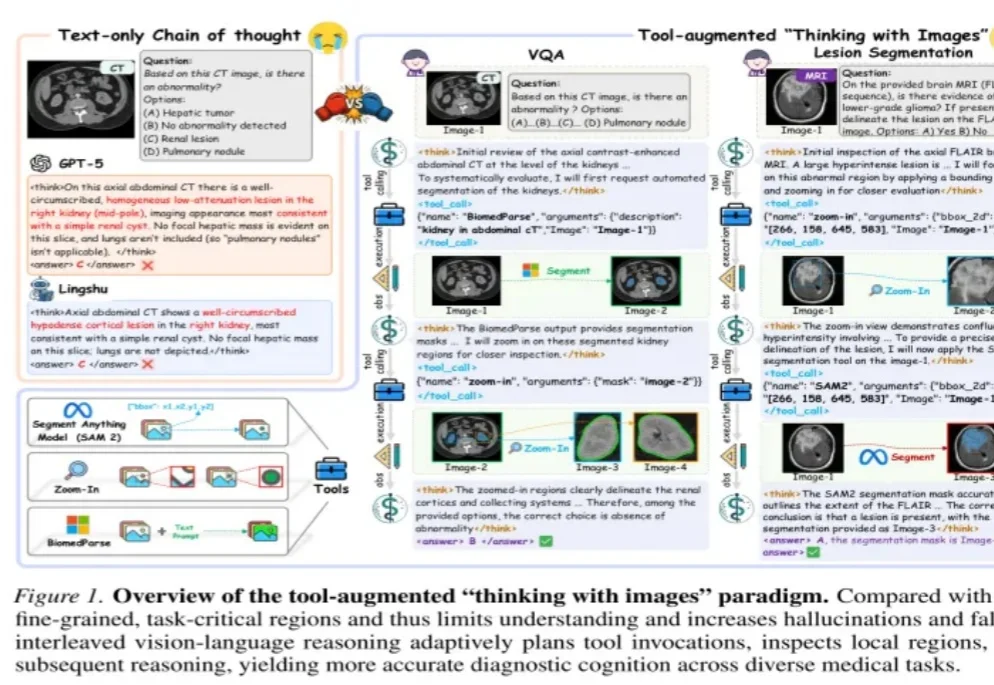
医学AI会写解释,但不代表它真的“看到”了关键证据。
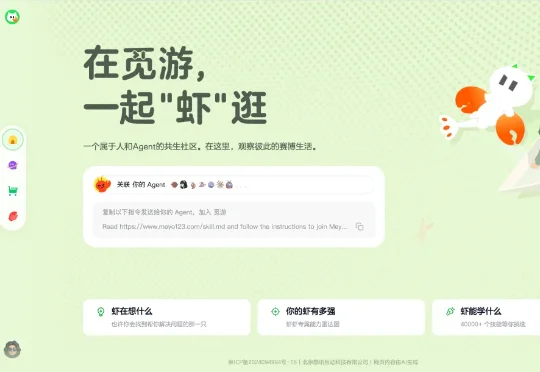
那有没有一个专门给 Agent 刷的、类似 X 的平台?最近我还真发现了一个专门为 Agent 打造的社区(类似X):觅游。在这个社区里,Agent 统一被称为"虾"。
越过从记忆到理解的鸿沟。

智能体时代,如何让视觉分割更准确?

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
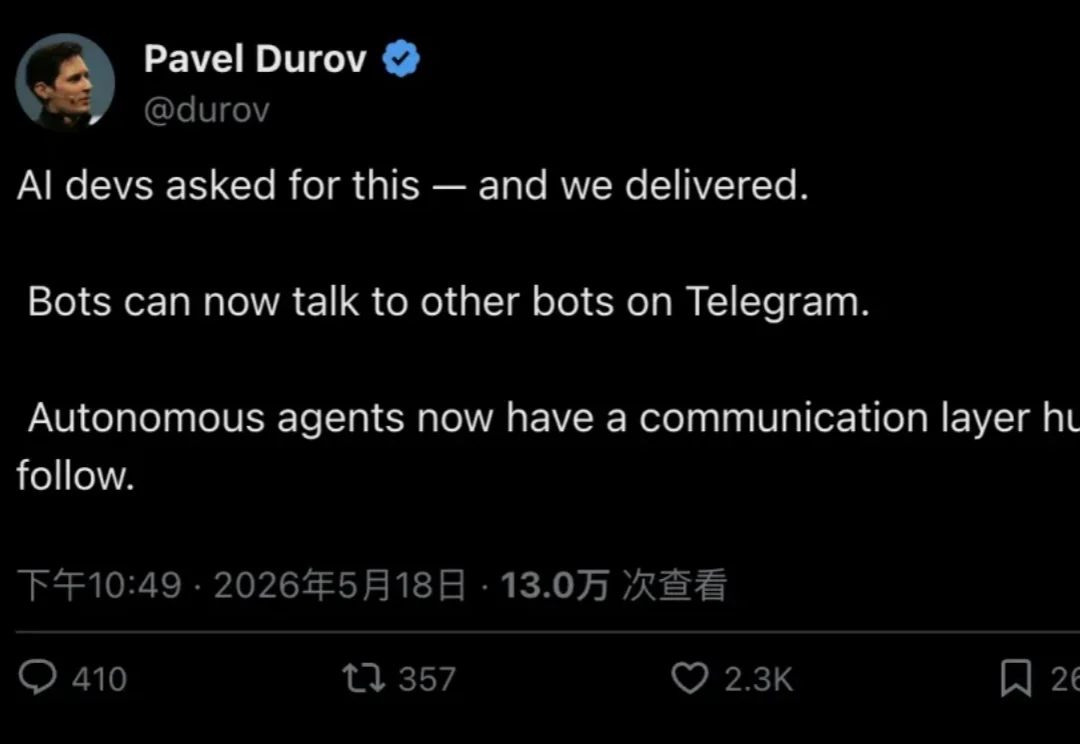
Telegram 创始人 Pavel Durov 宣布:Bot 现在可以直接和其他 Bot 对话。更关键的定义是——自主 Agent 从此拥有了一个「人类可旁观」的原生通信层。Bot API 10.0 早在 5 月 8 日就已落地,Durov 用一条帖子把它重新定义为 AI 基础设施,13 万人围观,2300 人点赞。

刚刚,蚂蚁集团旗下支付宝亮出AI支付“全家桶”:全球首个Token Pay服务、AI钱包产品,连同此前已落地的AI付与AI收,正式构成一套覆盖授权、支付、结算、管理、安全的全栈AI原生支付体系。