
斯坦福最新AI Agent序列化证伪假设检验自动化框架,向卡尔·波普尔致敬
斯坦福最新AI Agent序列化证伪假设检验自动化框架,向卡尔·波普尔致敬在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。
来自主题: AI技术研报
9785 点击 2025-02-23 11:13
 搜索
搜索
在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。
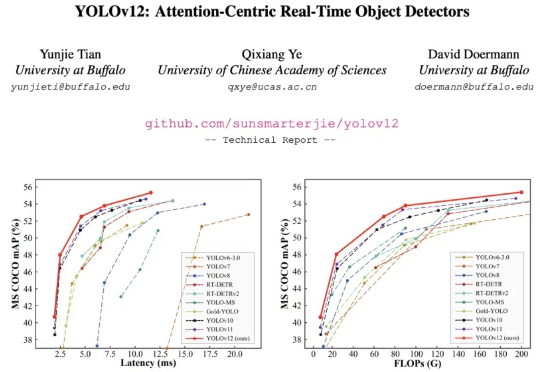
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。
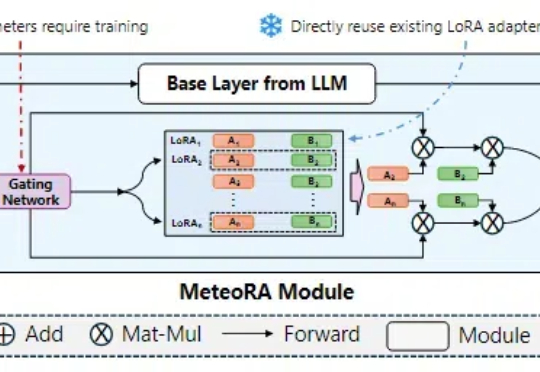
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
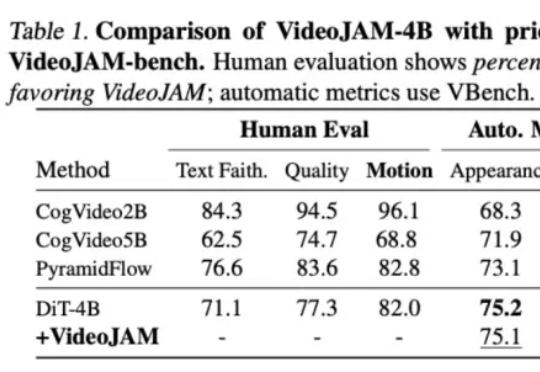
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满:
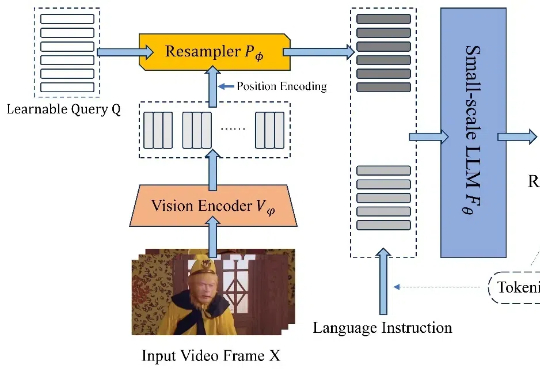
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。

周日晚间,五位高校教授夜话DeepSeek,从模型方法、框架、系统、基础设施等角度,阐述DeepSeek的技术原理与未来方向,揭秘其优化方法如何提升算力能效,信息量很大。

英伟达卡内基梅隆大学一起,给宇树机器人“一雪前耻”了(doge)。只通过一个训练框架,机器人就能成为“学人精”,完成各种高难度敏捷动作。

AI发展日新月异,未来扑朔迷离。近日,Web框架Django之父Simon Willison,预测了未来1、3、6年不同阶段的AI发展以及影响。