美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。
来自主题: AI资讯
9353 点击 2024-12-02 12:35
 搜索
搜索
Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。
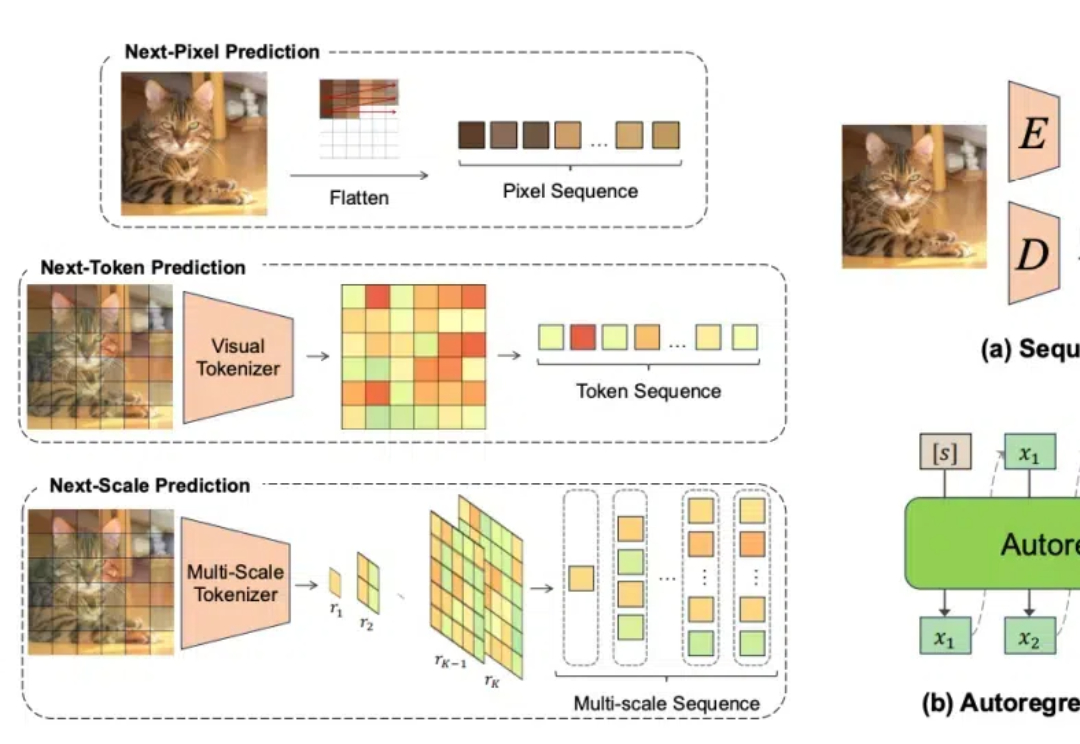
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。
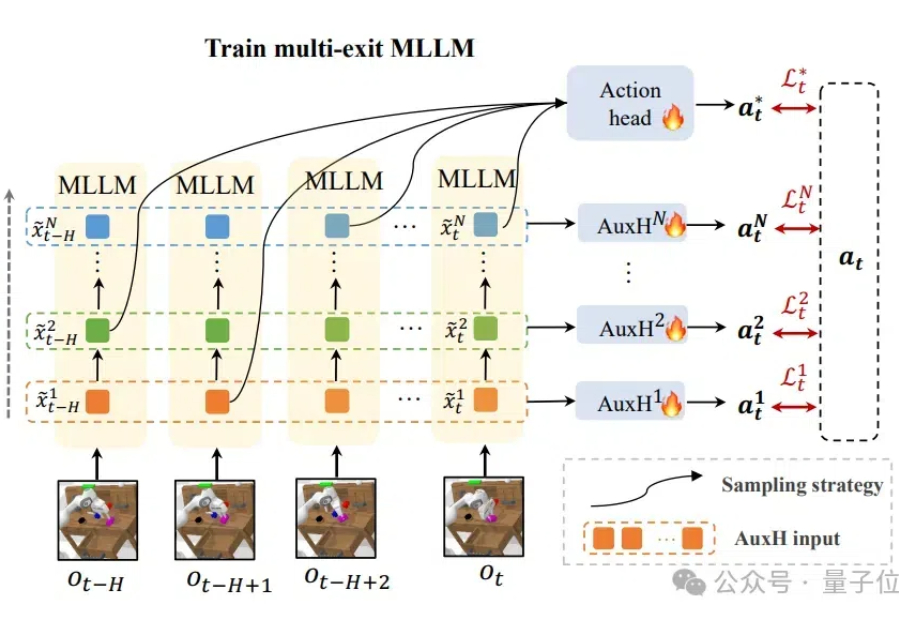
计算、存储消耗高,机器人使用多模态模型的障碍被解决了! 来自清华大学的研究者们设计了DeeR-VLA框架,一种适用于VLA的“动态推理”框架,能将LLM部分的相关计算、内存开销平均降低4-6倍。
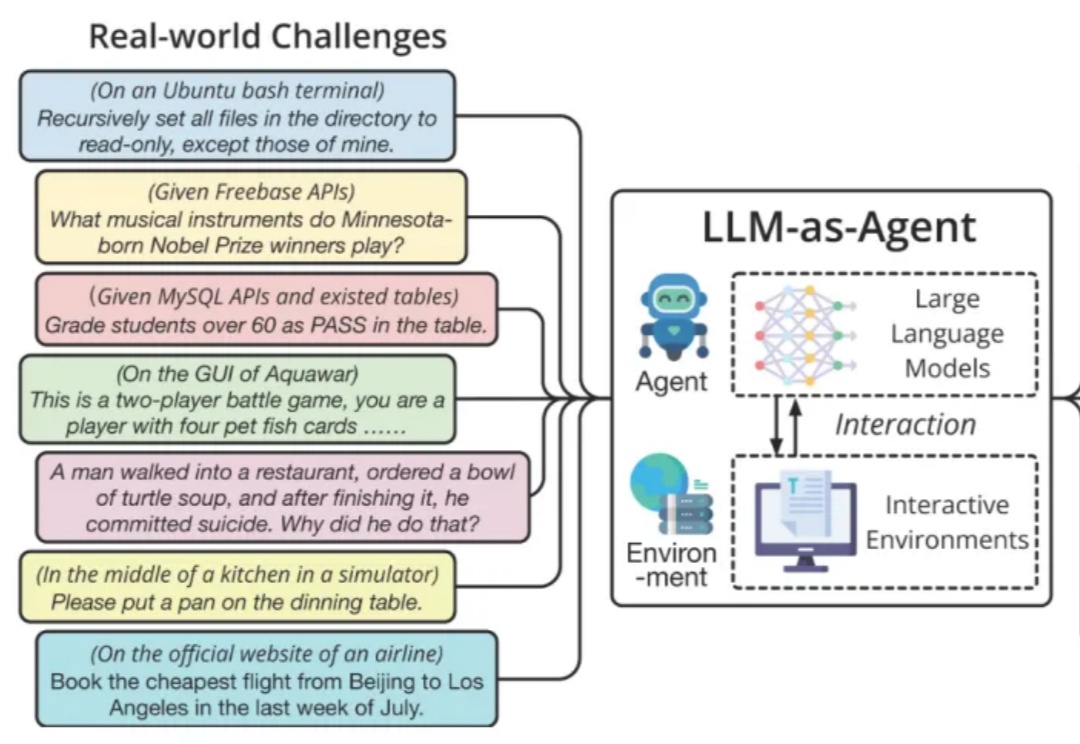
只需一次人类示范,就能让智能体适应新环境?
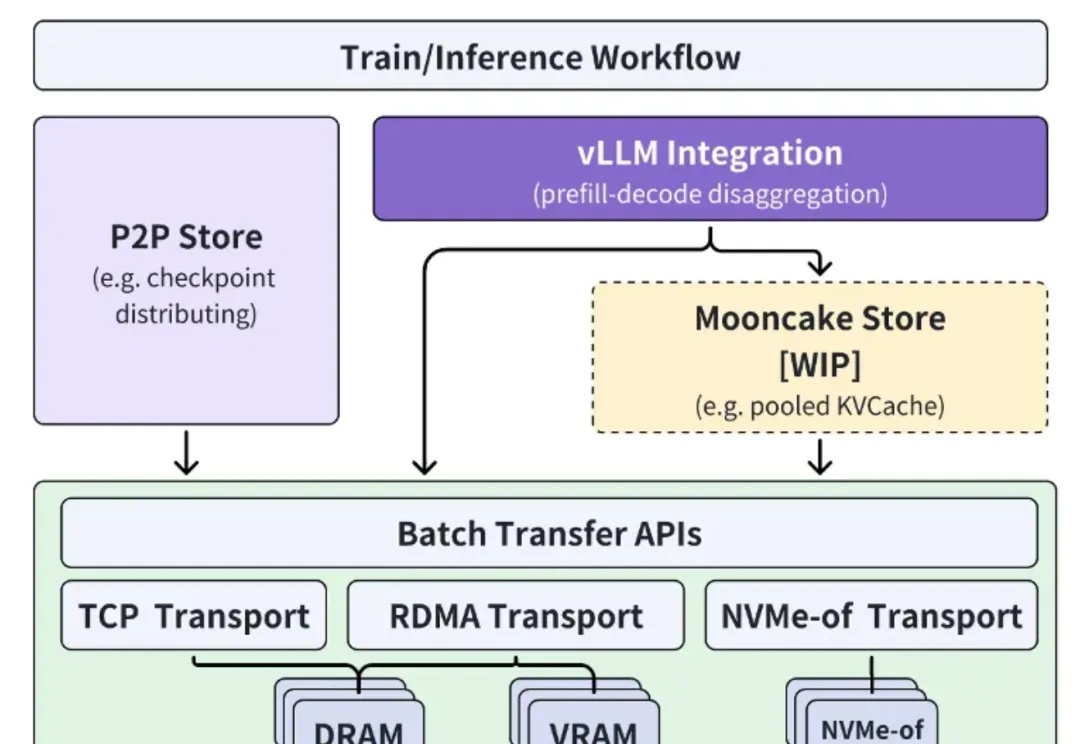
什么?Kimi底层推理架构刚刚宣布:开!源!了!
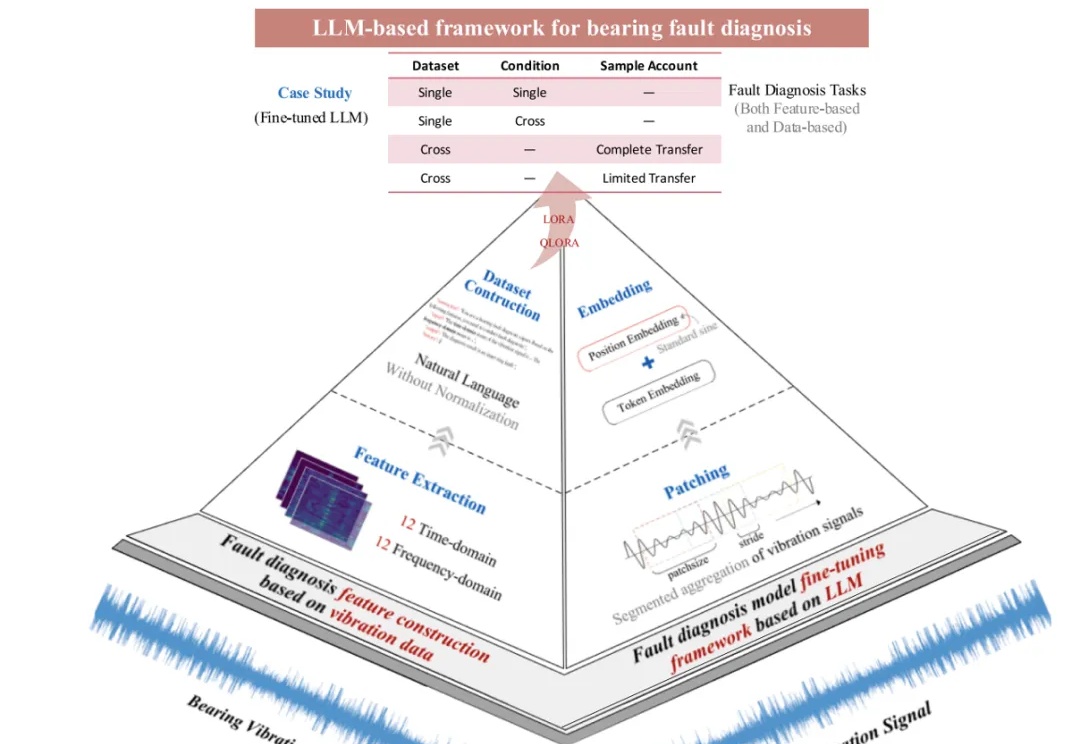
近日,《Mechanical System and Signal Processing》(MSSP)在线发表刊登北航 PHM 团队最新研究成果:基于大语言模型的轴承故障诊断框架(LLM-based Framework for Bearing Fault Diagnosis)。

新加坡国立大学刚刚推出的OminiControl框架无疑是AI P图的神器,轻松一键生成物体一致性的图像,例如产品效果图和试衣图。

这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。
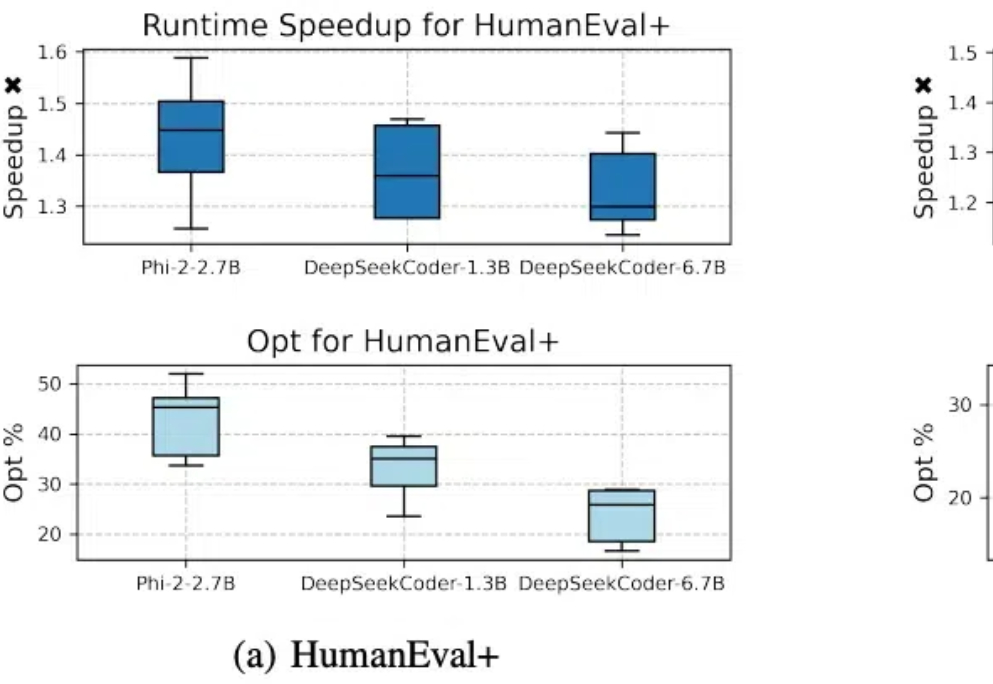
代码模型SFT对齐后,缺少进一步偏好学习的问题有解了。 北大李戈教授团队与字节合作,在模型训练过程中引入偏好学习,提出了一个全新的代码生成优化框架——CodeDPO。