
NeurIPS 2024 (Oral) | 如何量化与提升思维链的推理能力边界?
NeurIPS 2024 (Oral) | 如何量化与提升思维链的推理能力边界?该文章的第一作者陈麒光,目前就读于哈工大赛尔实验室。他的主要研究方向包括大模型思维链、跨语言大模型等。 该研究主要提出了推理边界框架(Reasoning Boundary Framework, RBF),首次尝试量化并优化思维链推理能力。
来自主题: AI技术研报
5745 点击 2024-11-10 13:50
 搜索
搜索
该文章的第一作者陈麒光,目前就读于哈工大赛尔实验室。他的主要研究方向包括大模型思维链、跨语言大模型等。 该研究主要提出了推理边界框架(Reasoning Boundary Framework, RBF),首次尝试量化并优化思维链推理能力。

来自美国医学院的研究团队聚焦于医学图像分割领域中人工智能基础模型的开发与应用,提供了一个全面的基础模型开发框架。
AI智能体能像有机生命一样自适应演化吗?最近清华大学团队提出了AgentSquare模块化智能体设计框架,通过标准化的模块接口抽象,让AI智能体可以通过模块演化和重组高速进化,实现针对不同任务场景的自适应演进,赋能超越人类设计的智能体系统在多种评测数据集上广泛自我涌现。

Lodge++ 是一个创新的舞蹈编排框架,旨在根据给定的音乐和期望的舞蹈风格生成高质量、超长且生动的舞蹈序列。
全新Agent框架,将知识图谱从知识获取来源直接升级为Agent编排引擎。 蚂蚁集团推出muAgent,兼容现有市面各类Agent框架,同时可实现复杂推理、在线协同、人工交互、知识即用四大核心差异技术功能。
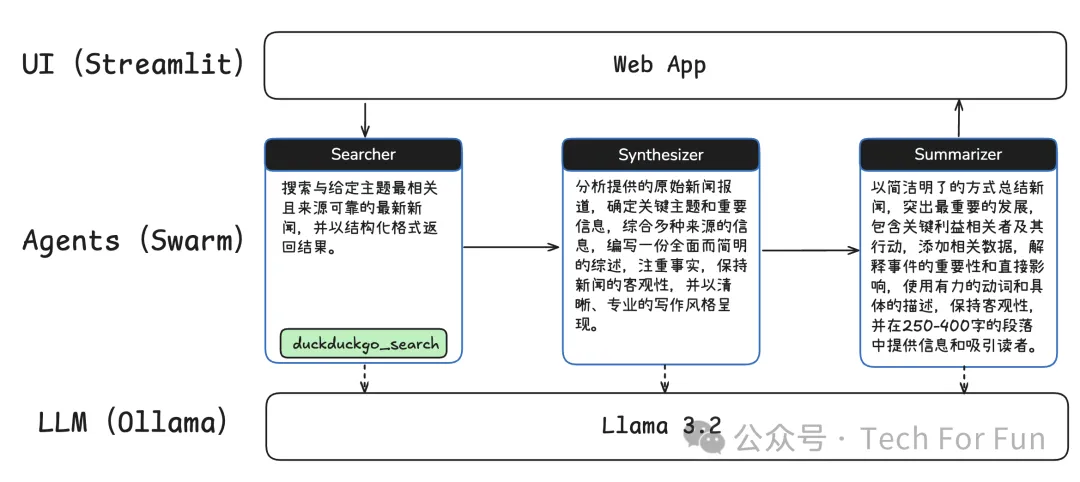
本文将带你构建一个多智能体新闻助理,利用 OpenAI 的 Swarm 框架和 Llama 3.2 来自动化新闻处理工作流。在本地运行环境下,我们将实现一个多智能体系统,让不同的智能体各司其职,分步完成新闻搜索、信息综合与摘要生成等任务,而无需付费使用外部服务。

基于这一理念,DeepMind团队开发了一个双系统框架,称为Talker-Reasoner,旨在模仿人类的这两种思维模式。

Bifröst 是一个创新的3D感知图像合成框架,它利用扩散模型来执行基于语言指令的图像合成任务。

近日,中科大王杰教授团队(MIRA Lab)和华为诺亚方舟实验室(Huawei Noah's Ark Lab)联合提出了可生成具有成千上万节点规模的神经电路生成与优化框架,具备高扩展性和高可解释性,这为新一代芯片电路逻辑综合工具奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

SegVG是一种新的视觉定位方法,通过将边界框注释转化为像素级分割信号来增强模型的监督信号,同时利用三重对齐模块解决特征域差异问题,提升了定位准确性。实验结果显示,SegVG在多个标准数据集上超越了现有的最佳模型,证明了其在视觉定位任务中的有效性和实用性。