
统一图像生成,无需繁杂插件!智源发布扩散模型框架OmniGen
统一图像生成,无需繁杂插件!智源发布扩散模型框架OmniGen多模态模型,统一图像生成。
来自主题: AI资讯
8124 点击 2024-10-30 13:39
 搜索
搜索
多模态模型,统一图像生成。
如何通过更好的提示工程来提升模型的推理能力,一直是研究人员和工程师们关注的重点。

Janus 是 DeepSeek AI 开发的一个先进的多模态理解和生成框架,它通过创新性地解耦视觉编码路径来应对多模态理解和生成任务之间的需求冲突。

LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
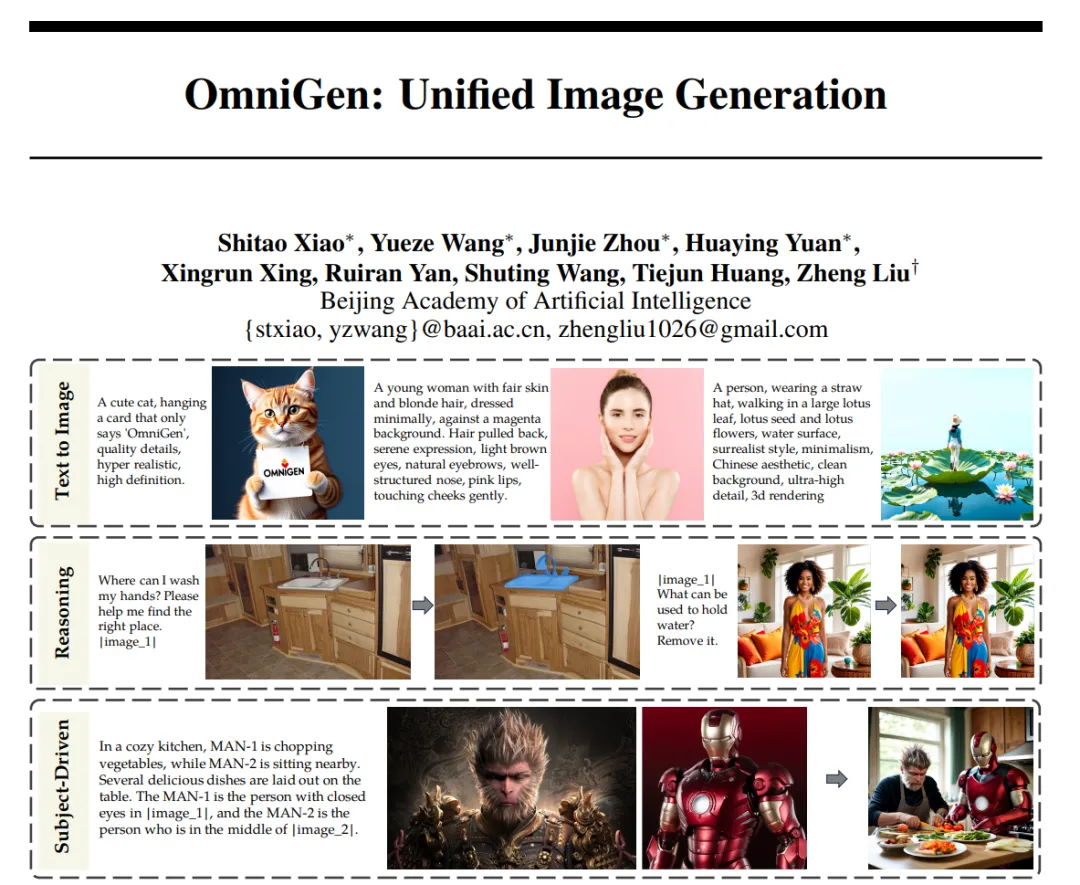
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。

近日,天桥脑科学研究院和普林斯顿大学等多所研究机构发布了一篇研究论文,详细阐述了长期记忆对 AI 自我进化的重要性,并且他们还提出了自己的实现框架 —— 基于多智能体的 Omne,其在 GAIA 基准上取得了第一名的成绩。
如果这项技术影响到了我,我对此有无发言权?

AI评估AI可靠吗?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。