
MotionClone:无需训练,一键克隆视频运动
MotionClone:无需训练,一键克隆视频运动无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。
来自主题: AI技术研报
7228 点击 2024-07-15 14:10
 搜索
搜索
无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

AI 代理得越来越重要,能够实现自主决策和解决问题。为了有效运作,这些代理需要一个确定最佳行动方案的规划过程,然后执行计划的行动。

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。

最近,新加坡国立大学联合南洋理工大学和哈工深的研究人员共同提出了一个全新的视频推理框架,这也是首次大模型推理社区提出的面向视频的思维链框架(Video-of-Thought, VoT)。视频思维链VoT让视频多模态大语言模型在复杂视频的理解和推理性能上大幅提升。该工作已被ICML 2024录用为Oral paper。
智能体又双叒叕进化了!这次,什么游戏都能玩,什么软件都能操控了。

近年来,人物动作生成的研究取得了显著的进展,在众多领域,如计算机视觉、计算机图形学、机器人技术以及人机交互等方面获得广泛的关注。然而,现有工作大多只关注动作本身,以场景和动作类别同时作为约束条件的研究依然处于起步阶段。

SelfGNN框架结合了图神经网络和个性化自增强学习,能够捕捉用户行为的多时间尺度模式,降低噪声影响,提升推荐系统鲁棒性。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。
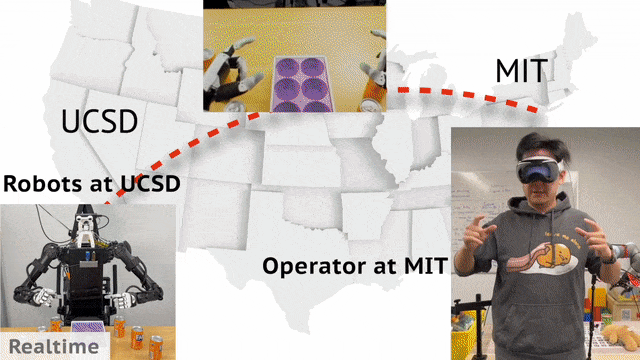
现实中,机器人收据收集可以通过远程操控实现。来自UCSD、MIT的华人团队开发了一个通用框架Open-TeleVision,可以让你身临其境操作机器人,即便相隔3000英里之外。

一转眼,2024 年已经过半。我们不难发现,AI 尤其是 AIGC 领域出现一个越来越明显的趋势:文生图赛道进入到了稳步推进、加速商业落地的阶段,但同时仅生成静态图像已经无法满足人们对生成式 AI 能力的期待,对动态视频的创作需求前所未有的高涨。