平替版Fable 5的打开教程来了:性能追平,成本砍半
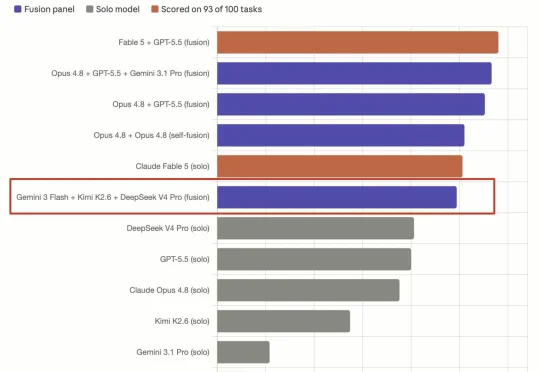
平替版Fable 5的打开教程来了:性能追平,成本砍半最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。
来自主题: AI资讯
9278 点击 2026-06-14 16:04