
Llama-2+Mistral+MPT=? 融合多个异构大模型显奇效
Llama-2+Mistral+MPT=? 融合多个异构大模型显奇效融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM
来自主题: AI技术研报
5704 点击 2024-01-27 13:51
 搜索
搜索
融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM

斯坦福炒菜机器人的大火,开启了2024年机器人元年。最近,CMU研究团队推出了一款能在开放世界完成任务的机器人,成本仅18万元。没见过的场景,它可以靠自学学会!

药物与靶标之间的结合亲和力的预测对于药物发现至关重要。然而,现有方法的准确性仍需提高。另一方面,大多数深度学习方法只关注非共价(非键合)结合分子系统的预测,而忽略了在药物开发领域越来越受到关注的共价结合的情况。

一张名为《大模型的深渊》的图,在去年广为流行。吃瓜群众惊诧地发现,原来绝大多数大模型,都挤在深不见底的层级,“宣称自己快要落地的”“再等等决定啥时候落地的”“什么落地不落地的”“怎么还有这么多没听说过的大模型啊”……
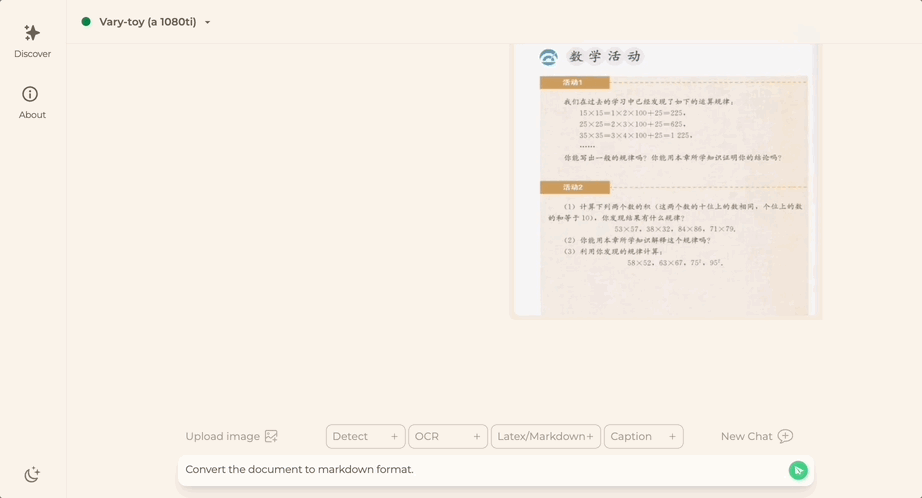
一款名为Vary-toy的“年轻人的第一个多模态大模型”来了!模型大小不到2B,消费级显卡可训练,GTX1080ti 8G的老显卡轻松运行。
直至2023年,大模型提出“重做一遍”的口号,将创业者拉回2015年遍地黄金时代,这是所有人的机会,也是时代再造英雄的时刻。
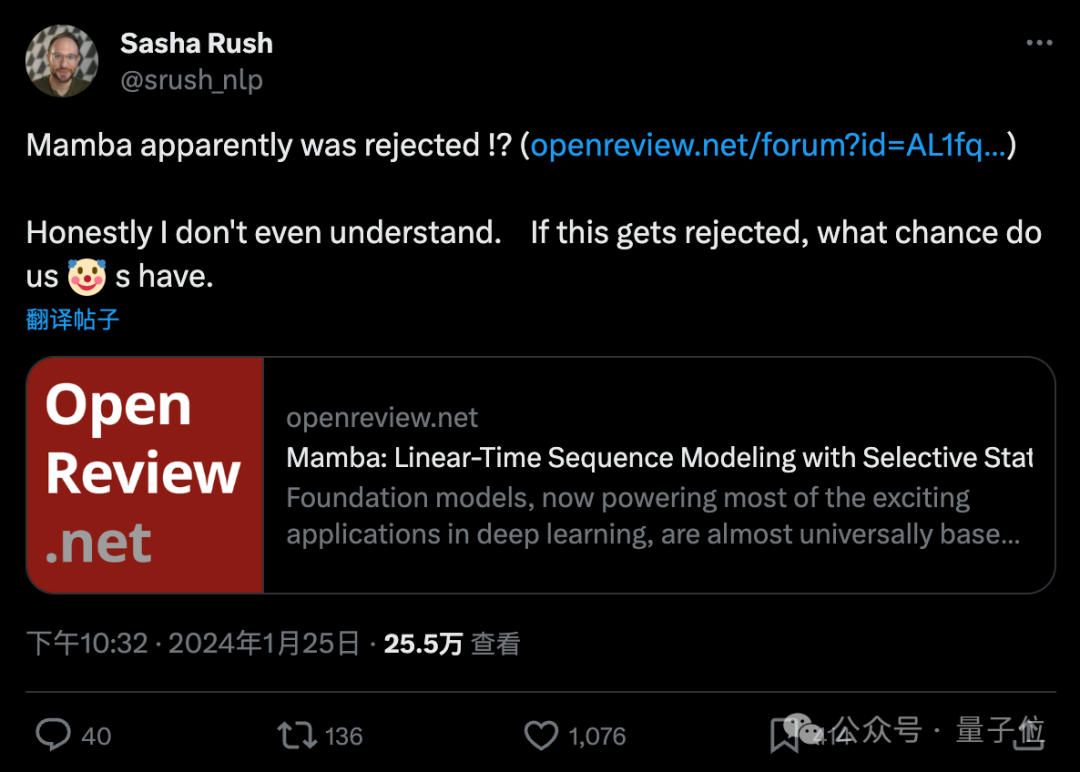
一项ICLR拒稿结果让AI研究者集体破防,纷纷刷起小丑符号。争议论文为Transformer架构挑战者Mamba,开创了大模型的一个新流派。发布两个月不到,后续研究MoE版本、多模态版本等都已跟上。

全新GPT-4 Turbo预览模型据介绍,该模型能更完整彻底地完成代码生成等任务,以减少模型未完成任务的“惰性”情况。

大神最新论文刚刚挂上arXiv,还是热乎的:解构扩散模型,提出一个高度简化的新架构l-DAE(小写的L)。

通义千问的图像推理能力,最近有了大幅提升。