
小米AI语音新框架:人人都能当声音导演
小米AI语音新框架:人人都能当声音导演语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。
来自主题: AI技术研报
10595 点击 2026-04-08 16:58
 搜索
搜索
语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?
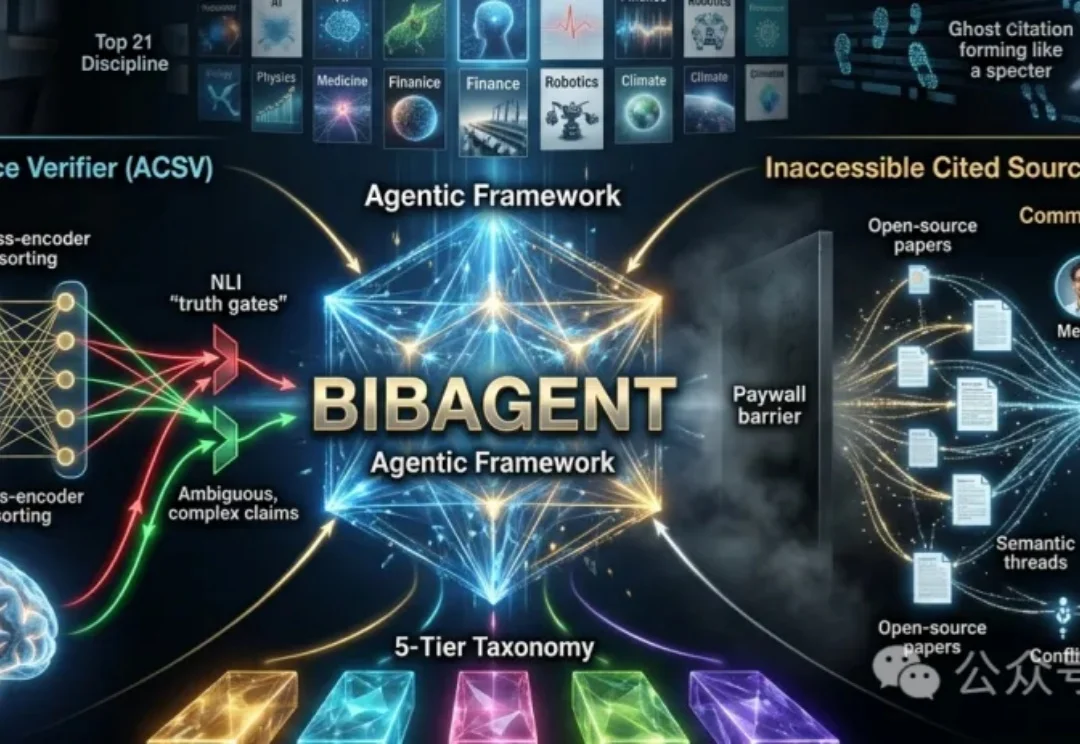
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?

面壁智能2B小模型VoxCPM 2惊艳开源,一众外国网友疯狂了!30种语言与9大方言它是信手拈来,复刻的贺炜激昂解说与徐志胜脱口秀,相似度简直直击灵魂。这哪是工具,分明是降维打击的生产力核武器!
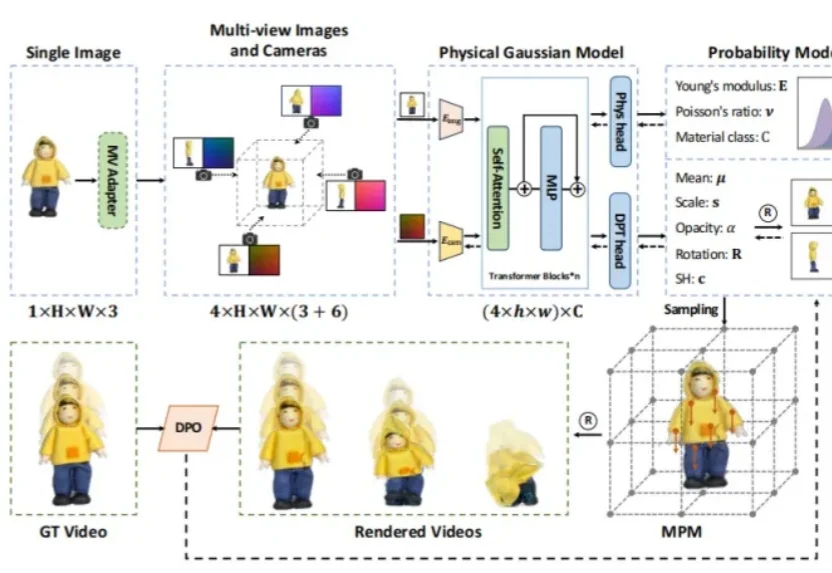
让静态的图片变成三维物体并动起来已经不算新鲜,但如果让图片不仅动起来,还能完美遵循现实世界的物理规律(比如蛋糕的Q弹、沙堆的散落、石雕的坚硬)呢?
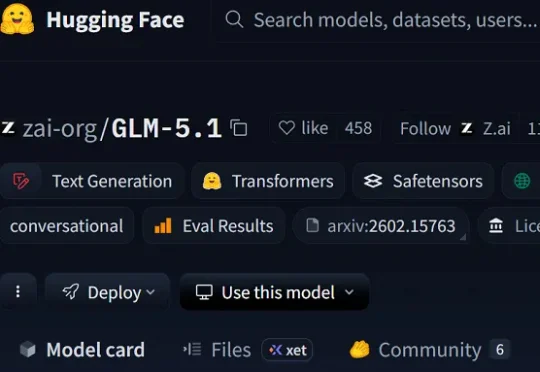
今天,智谱正式开源其最强模型GLM-5.1,这一模型在专业软件开发基准测试SWE-Bench Pro中,GLM-5.1刷新全球最佳成绩,得分达到58.4,超过了GPT-5.4、Claude Opus 4.6等已经正式发布的闭源模型,和MiniMax M2.7、Kimi K2.5等开源模型。

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
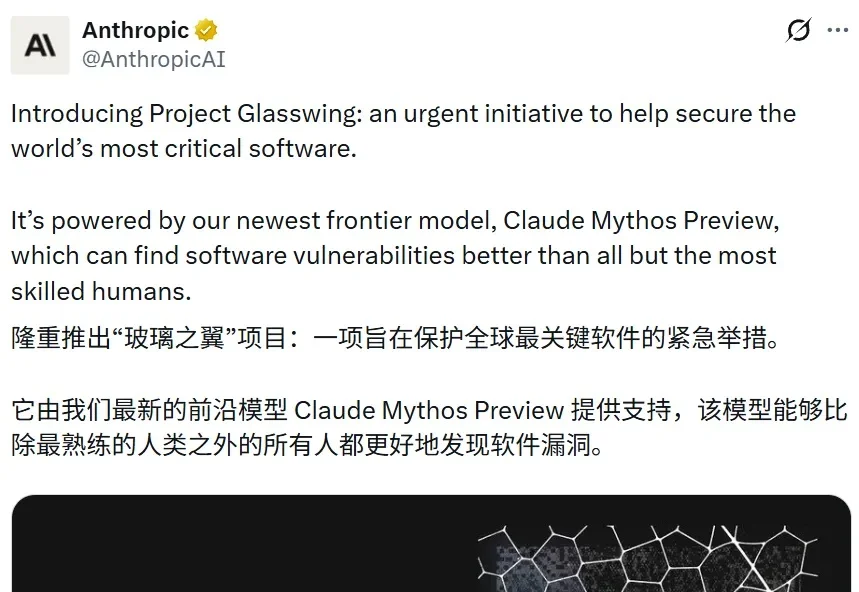
和之前 Claude Code 泄漏的代码揭示的一样,Claude Mythos 它真的来了。今天凌晨,Anthropic 发布了大量关于其新模型 Claude Mythos Preview 的信息(包含一份长达 244 页的系统卡)。同时,Anthropic 还宣布了一个基于此模型的 AI 网络安全项目 Project Glasswing。
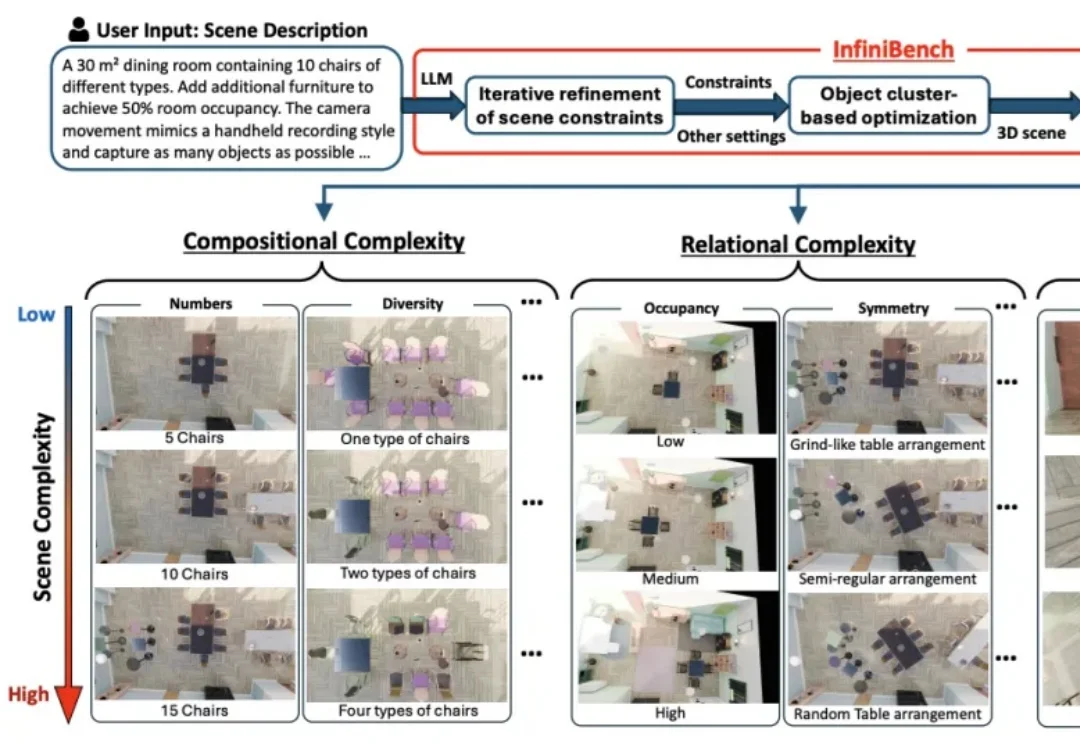
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。